Gestión de Memoria (página 2)
Una vez implementada la partición, hay dos maneras de asignar los procesos a ella. La primera es mediante el uso de una cola única (figura 2a) que asigna los procesos a los espacios disponibles de la memoria conforme se vayan desocupando. El tamaño del hueco de memoria disponible es usado para localizar en la cola el primer proceso que quepa en él. Otra forma de asignación es buscar en la cola el proceso de tamaño mayor que se ajuste al hueco, sin embargo hay que tomar en cuenta que tal método discrimina a los procesos más pequeños. Dicho problema podría tener solución si se asigna una partición pequeña en la memoria al momento de hacer la partición inicial, el cual sería exclusivo para procesos pequeños.

Fig. 2. (a) Particiones fijas en memoria con una cola única de entrada. (b) Particiones fijas en memoria con colas exclusivas para cada tamaño diferente de la partición. El espacio asignado a la partición 2 está en desuso.
Esta idea nos lleva a la implementación de otro método para particiones fijas, que es el uso de diferentes colas independientes (figura 2b) exclusivas para cierto rango en el tamaño de los procesos. De esta manera al llegar un proceso, éste sería asignado a la cola de tamaño más pequeño que la pueda aceptar. La desventaja en esta organización es que si una de las colas tiene una larga lista de procesos en espera, mientras otra cola esta vacía, el sector de memoria asignado para ese tamaño de procesos estaría desperdiciándose.
CON INTERCAMBIO
1.2.1.- Multiprogramación con particiones variables
Este esquema fue originalmente usado por el sistema operativo IBM OS/360 (llamado MFT), el cual ya no está en uso.
El sistema operativo lleva una tabla indicando cuáles partes de la memoria están disponibles y cuáles están ocupadas. Inicialmente, toda la memoria está disponible para los procesos de usuario y es considerado como un gran bloque o hueco único de memoria. Cuando llega un proceso que necesita memoria, buscamos un hueco lo suficientemente grande para el proceso. Si encontramos uno, se asigna únicamente el espacio requerido, manteniendo el resto disponible para futuros procesos que requieran de espacio.
Consideremos el ejemplo de la figura 3, en donde se cuenta un espacio reservado para el sistema operativo en la memoria baja de 400K y un espacio disponible para procesos de usuario de 2160K, siendo un total de memoria del sistema de 2560K. Dada la secuencia de procesos de la figura y usando un algoritmo de First Come – First Served (FCFS) se puede asignar de inmediato memoria a los procesos P1, P2 y P3, creando el mapa de memoria de la figura 4(a) en el cual queda un hueco de 260K que ya no puede ser utilizado por el siguiente proceso dado que no es suficiente para abarcarlo.
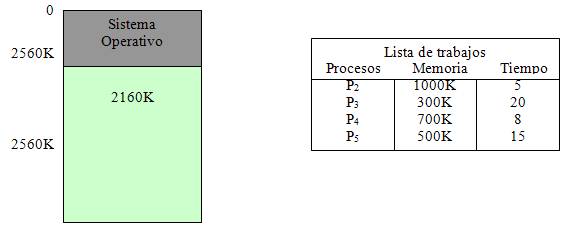
Fig. 3. Ejemplo de una división inicial de memoria y una lista de trabajos.

Fig. 4. Ejemplo de asignación de procesos en la memoria principal.
Usando un proceso de asignación Round-Robin con un quantum de 1 unidad de tiempo, el proceso P2 terminaría en la unidad de tiempo 14, liberando esa cantidad de memoria, como se muestra en la figura 4(b). Entonces el sistema operativo checa la lista de trabajos y asigna el siguiente proceso que quepa en el espacio de memoria liberado. El proceso P4 produce el mapa de memoria que se muestra en la figura 4(c). El proceso P1 terminará en la unidad de tiempo 28 para producir el mapa de la figura 4(d) y entonces se asigna el proceso P5 generando el mapa de la figura 4(e).
Cuando a un proceso se le asigna un espacio y es cargado a la memoria principal, puede entonces competir para el uso del CPU.
1.2.1.1.- Compactación de memoria
Cuando un proceso llega y necesita memoria, el sistema operativo busca en la tabla de huecos alguno lo suficientemente grande para el proceso. Si el hueco es muy grande, lo parte en dos. Una parte es asignada al proceso y la otra se identifica como hueco. Cuando el proceso termina y la memoria es liberada, el espacio es identificado como un hueco más en la tabla y si el nuevo hueco es adyacente con otro, ambos huecos se unen formando un solo hueco más grande. En ese momento se debe de checar si no existen procesos a los que este nuevo hueco pueda darles cabida.

Fig. 5. Ejemplo de compactación de huecos no adyacentes.
En la figura 5 se muestra como se modifica el mapa de la memoria después de compactar huecos no adyacentes generados después de intercambios realizados en el ejemplo de la figura 4.
1.2.1.2.- Asignación dinámica
El proceso de compactación del punto anterior es una instancia particular del problema de asignación de memoria dinámica, el cual es el cómo satisfacer una necesidad de tamaño n con una lista de huecos libres. Existen muchas soluciones para el problema. El conjunto de huecos es analizado para determinar cuál hueco es el más indicado para asignarse. Las estrategias más comunes para asignar algún hueco de la tabla son:
Primer ajuste: Consiste en asignar el primer hueco con capacidad suficiente. La búsqueda puede iniciar ya sea al inicio o al final del conjunto de huecos o en donde terminó la última búsqueda. La búsqueda termina al encontrar un hueco lo suficientemente grande.
Mejor ajuste: Busca asignar el espacio más pequeño de los espacios con capacidad suficiente. La búsqueda se debe de realizar en toda la tabla, a menos que la tabla esté ordenada por tamaño. Esta estrategia produce el menor desperdicio de memoria posible.
Peor ajuste: Asigna el hueco más grande. Una vez más, se debe de buscar en toda la tabla de huecos a menos que esté organizada por tamaño. Esta estrategia produce los huecos de sobra más grandes, los cuales pudieran ser de más uso si llegan procesos de tamaño mediano que quepan en ellos.
Se ha demostrado mediante simulacros que tanto el primer y el mejor ajuste son mejores que el peor ajuste en cuanto a minimizar tanto el tiempo del almacenamiento. Ni el primer o el mejor ajuste es claramente el mejor en términos de uso de espacio, pero por lo general el primer ajuste es más rápido.
1.2.2.- Administración de la memoria con mapas de bits
Este tipo de administración divide la memoria en unidades de asignación, las cuales pueden ser tan pequeñas como unas cuantas palabras o tan grandes como varios kilobytes. A cada unidad de asignación le corresponde un bit en el mapa de bits, el cual toma el valor de 0 si la unidad está libre y 1 si está ocupada (o viceversa). La figura 6 muestra una parte de la memoria y su correspondiente mapa de bits.

Fig. 6. Ejemplo de un mapa de bits para la administración de la memoria.
Un mapa de bits es una forma sencilla para llevar un registro de las palabras de la memoria en una cantidad fija de memoria, puesto que el tamaño del mapa sólo depende del tamaño de la memoria y el tamaño de la unidad de asignación.
1.2.3.- Administración de la memoria con listas ligadas
Otra forma de mantener un registro de la memoria es mediante una lista ligada de los segmentos de memoria asignados o libres, en donde un segmento puede ser un proceso o un hueco entre dos procesos. La memoria de la figura 7(a) está mostrada como una lista ligada de segmentos en la figura 7(b). Cada entrada de la lista especifica un hueco (H) o un proceso (P), la dirección donde comienza, su longitud y un apuntador a la siguiente entrada.

Fig. 7. Ejemplo de listas ligadas.
En este ejemplo, la lista de segmentos está ordenada por direcciones, lo que da la ventaja de que al terminar o intercambiar un proceso, la actualización de la lista es directa.
1.2.4.- Asignación del hueco de intercambio
En algunos sistemas, cuando el proceso se encuentra en la memoria, no hay un hueco en el disco asignado a él. Cuando deba intercambiarse, se deberá asignar un hueco para él en el área de intercambio del disco. Los algoritmos para la administración del hueco de intercambio son los mismos que se utilizan para la administración de la memoria principal.
En otros sistemas, al caerse un proceso, se le asigna un hueco de intercambio en el disco. Cuando el proceso sea intercambiado, siempre pasará al hueco asignado, en vez de ir a otro lugar cada vez. Cuando el proceso concluya, se libera el hueco de intercambio. La única diferencia es que el hueco en disco necesario para un proceso debe representarse como un número entero de bloques del disco. Por ejemplo, un proceso de 13.5 K debe utilizar 14K (usando bloques de 1K).
1.2.5.- Fragmentación
La fragmentación es la memoria que queda desperdiciada al usar los métodos de gestión de memoria que se vieron en los métodos anteriores. Tanto el primer ajuste, como el mejor y el peor producen fragmentación externa.
La fragmentación es generada cuando durante el reemplazo de procesos quedan huecos entre dos o más procesos de manera no contigua y cada hueco no es capaz de soportar ningún proceso de la lista de espera. Tal vez en conjunto si sea espacio suficiente, pero se requeriría de un proceso de defragmentación de memoria o compactación para lograrlo. Esta fragmentación se denomina fragmentación externa.
Existe otro tipo de fragmentación conocida como fragmentación interna, la cual es generada cuando se reserva más memoria de la que el proceso va realmente a usar. Sin embargo a diferencia de la externa, estos huecos no se pueden compactar para ser utilizados. Se debe de esperar a la finalización del proceso para que se libere el bloque completo de la memoria.
MEMORIA VIRTUAL
PAGINACIÓN
Hasta ahora, los métodos que hemos visto de la administración de la memoria principal, nos han dejado con un problema: fragmentación, (huecos en la memoria que no pueden usarse debido a lo pequeño de su espacio) lo que nos provoca un desperdicio de memoria principal.
Una posible solución para la fragmentación externa es permitir que espacio de direcciones lógicas lleve a cabo un proceso en direcciones no contiguas, así permitiendo al proceso ubicarse en cualquier espacio de memoria física que esté disponible, aunque esté dividida. Una forma de implementar esta solución es a través del uso de un esquema de paginación. La paginación evita el considerable problema de ajustar los pedazos de memoria de tamaños variables que han sufrido los esquemas de manejo de memoria anteriores. Dado a sus ventajas sobre los métodos previos, la paginación, en sus diversas formas, es usada en muchos sistemas operativos.
Al utilizar la memoria virtual, las direcciones no pasan en forma directa al bus de memoria, sino que van a una unidad administradora de la memoria (MMU –Memory Management Unit). Estas direcciones generadas por los programas se llaman direcciones virtuales y conforman el hueco de direcciones virtuales. Este hueco se divide en unidades llamadas páginas. Las unidades correspondientes en la memoria física se llaman marcos para página o frames. Las páginas y los frames tienen siempre el mismo tamaño.
2.1.1.- Tablas de páginas
Cada página tiene un número que se utiliza como índice en la tabla de páginas, lo que da por resultado el número del marco correspondiente a esa página virtual. Si el bit presente / ausente es 0, se provoca un señalamiento (trap) hacia el sistema operativo. Si el bit es 1, el número de marco que aparece en la tabla de páginas se copia en los bits de mayor orden del registro de salida, junto con el ajuste (offset) de 12 bits, el cual se copia sin modificaciones de la dirección virtual de entrada. Juntos forman una dirección física de 15 bits. El registro de salida se coloca entonces en el bus de la memoria como la dirección en la memoria física.
En teoría, la asociación de las direcciones virtuales con las físicas se efectúa según lo descrito. El número de página virtual se divide en un número de página virtual (los bits superiores)y un ajuste (los bits inferiores). El número de página virtual se utiliza como un índice en la tabla de páginas para encontrar la entrada de esa página virtual. El número de marco (si existe) se determina a partir de la tabla de páginas. El número de marco se asocia al extremo superior del ajuste y reemplaza al número de página virtual para formar una dirección física que se puede enviar a la memoria.
La finalidad de la tabla de páginas es asociar las páginas virtuales con los marcos. En términos matemáticos, la tabla de páginas es una función, cuyo argumento es el número de página virtual y como resultado el número del marco físico. Mediante el resultado de esta función, se puede reemplazar el campo de la página virtual de una dirección virtual por un campo de marco, lo que produce una dirección en la memoria física. Sin embargo hay que enfrentar dos aspectos fundamentales:
1. La tabla de páginas puede ser demasiado grande.
2. La asociación debe ser rápida.
El primer punto proviene del hecho de que las computadoras modernas utilizan direcciones virtuales de al menos 32 bits. Por ejemplo, si el tamaño de página es de 4K, un hueco de direcciones de 32 bits tiene un millón de páginas; en el caso de un hueco de direcciones de 64 bits, se tendría más información de la que uno quisiera contemplar.
El segundo punto es consecuencia del hecho de que la asociación virtual – física debe hacerse en cada referencia a la memoria. Una instrucción común tiene una palabra de instrucción y también un operando de memoria. Entonces es necesario hacer una, dos o más referencias a la tabla de páginas por cada instrucción.
2.1.2.- Algoritmos de reemplazo de páginas
Con el uso del método de paginación se puede llegar a saturar la memoria si se incrementa demasiado el nivel de multiprogramación. Por ejemplo, si se corren seis procesos, cada uno con un tamaño de diez páginas de las cuales en realidad sólo utiliza cinco, se tiene un mayor uso del CPU y con marcos de sobra. Pero pudiera suceder que cada uno de esos procesos quiera usar las diez páginas resultando en una necesidad de 60 marcos, cuando solo hay 40 disponibles.
Esto provoca sobre-asignación y mientras un proceso de usuario se está ejecutando, ocurre un fallo de página. El hardware se bloquea con el sistema operativo, el cual checa en sus tablas internas y se da cuenta que es un fallo de página y no un acceso ilegal de memoria. El sistema operativo determina si la página está residiendo en disco, pero también determina que no hay marcos de memoria disponibles en la lista de marcos libres.
Al ocurrir el fallo de página, el sistema operativo debe elegir una página para retirarla de la memoria y usar el espacio para la página que se necesita para desbloquear el sistema y que el hardware pueda seguir trabajando. Si la página por eliminar de la memoria fue modificada, se debe volver a escribir al disco para mantener la información actualizada; de lo contrario, si la página no fue modificada no es necesario rescribir la información a disco y la página que se carga simplemente se escribe sobre la página a borrar en memoria. La figura 8 muestra gráficamente un intercambio de páginas entre la memoria principal y el disco (memoria secundaria).

Fig. 8. Se elimina de la memoria principal una página que no esté en uso y se reemplaza por una página de la cual el sistema operativo tiene necesidad de uso.
2.1.2.1.- Algoritmo aleatorio
Este algoritmo consiste simplemente en reemplazar aleatoriamente cualquier página de la memoria principal, sin hacer ningún esfuerzo de predicción.
Es el algoritmo más sencillo dado que no requiere tener ninguna información, sin embargo, por no hacer uso de dicha información sobre el comportamiento del proceso, no puede lograr un buen desempeño.
2.1.2.2.- Algoritmo de reemplazo de páginas óptimo
Este algoritmo debe de tener el menor índice de fallos de página de todos los algoritmos. En teoría, este algoritmo debe de reemplazar la página que no va a ser usada por el periodo más largo de tiempo.
Desafortunadamente, el algoritmo de reemplazo óptimo es fácil en teoría, pero prácticamente imposible de implementar, dado que requiere conocer a futuro las necesidades del sistema.
Tal algoritmo existe y ha sido llamado OPT o MIN, pero se usa únicamente para estudios de comparaciones. Por ejemplo, puede resultar muy útil saber que aunque algún nuevo algoritmo no sea óptimo, está entre el 12.3% del óptimo y entre el 4.7% en promedio.
2.1.2.3.- Algoritmo de reemplazo de páginas según el uso no tan reciente
Este algoritmo hace uso de los dos bits de estado que están asociados a cada página. Estos bits son: R, el cual se activa cuando se hace referencia (lectura / escritura) a la página asociada; y M, que se activa cuando la página asociada es modificada (escritura). Estos bits deben de ser actualizado cada vez que se haga referencia a la memoria, por esto es de suma importancia que sean activados por el hardware. Una vez activado el bit, permanece en ese estado hasta que el sistema operativo, mediante software, modifica su estado.
Estos bits pueden ser utilizados para desarrollar un algoritmo de reemplazo que cuando inicie el proceso, el sistema operativo asigne un valor de 0 a ambos bits en todas las páginas. En cada interrupción de reloj, limpie el bit R para distinguir cuáles páginas tuvieron referencia y cuáles no.
Cuando ocurre un fallo de página, el sistema operativo revisa ambos bits en todas las páginas y las clasifica de la siguiente manera:
Clase 0: La página no ha sido referenciada, ni modificada.
Clase 1: La página no ha sido referenciada, pero ha sido modificada.
Clase 2: La página ha sido referenciada, pero no ha sido modificada.
Clase 3: La página ha sido referenciada y también modificada.
Una vez obtenida la clasificación, elimina una página de manera aleatoria de la primera clase no vacía con el número más pequeño. Esto porque para el algoritmo es mejor eliminar una página modificada sin referencias en al menos un intervalo de reloj, que una página en blanco de uso frecuente.
A pesar de que este algoritmo no es el óptimo, es fácil de implementar y de comprender y con mucha frecuencia es el más adecuado.
2.1.2.4.- Algoritmo de reemplazo "Primero en entrar, primero en salir" (FIFO)
El algoritmo más sencillo para remplazo de páginas es el FIFO (First In – First Out). Este algoritmo asocia a cada página el momento en que ésta fue traída a memoria. Cuando una página debe ser reemplazada se selecciona a la más antigua.
No es estrictamente necesario registrar el momento de entrada de la página a memoria, sino que se puede crear una cola en la que se van agregando las páginas conforme van llegando a la memoria. Cuando se debe eliminar una página, se selecciona la que está al frente de la lista (o sea, la más antigua de la lista). Cuando llega una página nueva, se inserta en la parte trasera de la cola. En la figura 9 se representa el funcionamiento de éste algoritmo.

Fig. 9. Reemplazo de páginas mediante el algoritmo FIFO.
Al igual que el algoritmo aleatorio, este algoritmo es fácil de comprender y de programar. Sin embargo, su desempeño no siempre es del todo bueno. La página reemplazada puede ser un módulo de inicialización que fue usado hace mucho tiempo y ya no se tiene necesidad de él. Por otro lado, puede contener una variable de uso muy frecuente que fue inicializada de manera temprana y está en uso constante.
2.1.2.5.- Algoritmo de reemplazo de páginas de la segunda oportunidad
Este algoritmo es una modificación del FIFO. El algoritmo hace uso del bit de referencia de la página. Cuando una página ha sido seleccionada para reemplazo, se revisa el bit de referencia. Si tiene valor de 0, se procede a reemplazar la página. Si por el contrario, el bit de referencia es 1 se le da a la página una segunda oportunidad.

Fig. 10. Algoritmo de la segunda oportunidad.
Cuando esto sucede, se le cambia el bit de referencia a 0 y se actualiza su tiempo de llegada al tiempo actual para que la página se colocada al final de la cola. De esta manera, la página espera todo un ciclo completo de páginas para ser entonces reemplazada.
Si la página tiene un uso muy frecuente, el bit de referencia se mantendría constantemente en 1 y la página no sería reemplazada. En la figura 10 se puede apreciar el funcionamiento del algoritmo.
2.1.2.6.- Algoritmo de reemplazo de páginas del reloj
Modificando el algoritmo de la segunda oportunidad (que a su vez es una modificación de FIFO) obtenemos el algoritmo aumentado de la segunda oportunidad o algoritmo del reloj. Usamos la misma clasificación vista en el algoritmo de uso no tan reciente (sección 2.1.2.3.).
Este algoritmo organiza las páginas en una lista circular como se muestra en la figura 11 y se usa un apuntador (o manecilla) que señala a la página más antigua.

Fig. 11. Algoritmo de reloj.
Cuando se presenta un fallo de página, el algoritmo revisa la página a la que está apuntando la manecilla. Si el bit de referencia es 0, la página es reemplazada con la nueva y la manecilla avanza una posición. Si el bit es 1, entonces se limpia (cambia a 0) y la manecilla avanza a la siguiente página y así sucesivamente hasta encontrar una con bit 0.
2.1.2.7.- Algoritmo de reemplazo de páginas "la de menor uso reciente" (LRU)
Este algoritmo es una buena aproximación al óptimo y se basa en al observación de que las páginas de uso frecuente en las últimas instrucciones se utilizan con cierta probabilidad en las siguientes. De la misma manera, es probable que las páginas que no hayan sido utilizadas durante mucho tiempo permanezcan sin uso por bastante tiempo. Implementando el algoritmo con esta base, al ocurrir un fallo de página, se elimina la página que no haya sido utilizada durante el tiempo más grande. De ahí su denominación: menor uso reciente (LRU – Least Recent Use).
A diferencia de los algoritmos anteriores, el LRU tiene un mejor rendimiento en cuanto al tiempo de aprovechamiento del CPU y del uso de la memoria. Sin embargo, el problema con este algoritmo es que su implementación es muy cara, ya que requiere de una asistencia considerable de hardware. Otro problema es el de determinar un orden para los marcos definido por el tiempo de menor uso. Para éste último hay dos posibles implementaciones:
Contadores: En el caso más sencillo, se asocia cada entrada tabla-página un campo de tiempo-de-uso y se le agrega al CPU un reloj lógico o contador. Este reloj es incrementado en cada referencia de memoria. Siempre que se hace referencia a una página, el contenido del registro del reloj es copiado al campo de tiempo-de-uso en la tabla de páginas para esa página. De esta forma, siempre se dispone del "tiempo" de la última referencia a cada página. La página que se reemplaza es la del menor valor de tiempo. Este esquema requiere de una búsqueda en toda la tabla de páginas para encontrar la página LRU, y una escritura en memoria al campo de tiempo-de-uso en la tabla de páginas por cada acceso a memoria. Los tiempos también se deben de mantener cuando las tablas de páginas son alteradas (debido a organización del CPU). Se debe considerar la posibilidad de sobrecarga en el reloj.
Pilas: Otra aproximación para implementar el reemplazo LRU es la de tener una pila con los números de páginas. Siempre que se hace referencia a una página, se quita de la pila y se pone en la parte superior. De esta manera, la parte superior de la pila es la página de uso más reciente y la de abajo es la LRU, tal como se muestra en la figura 12.

Fig. 12. Uso de pilas en el algoritmo LRU
SEGMENTACIÓN
Otra opción para el manejo de la memoria es usar una forma de liberar al programador de la tarea del control de las tablas en expansión y contracción, de la misma forma que la memoria virtual elimina la preocupación por organizar el programa en una serie de proyectos.
Esto se puede lograr dotando a la máquina de varios espacios independientes de direcciones llamados segmentos. Cada segmento tiene una serie lineal de direcciones, desde 0 hasta cierto máximo. La longitud de cada segmento puede variar de 0 hasta un máximo permitido. Los distintos segmentos pueden tener y de hecho tienen por lo general, longitudes distintas. Además, la longitud de un segmento puede variar durante la ejecución. La longitud de un segmento de la pila puede crecer si algo entra a la pila y decrecer si algo sale de ella.
Puesto que cada segmento constituye un espacio independiente de direcciones, los distintos segmentos pueden crecer o reducirse en forma independiente sin afectar a los demás. En la figura 13 podemos ver una lista de comparación entre la paginación y la segmentación.
La segmentación también facilita el uso de procedimientos o datos compartidos entre varios procesos. Un ejemplo común son las bibliotecas compartidas (Shared DLL"s). Es frecuente que las estaciones de trabajo modernas que ejecutan sistemas avanzados, con ventanas, tengan bibliotecas gráficas de tamaño muy grande que se compilan casi en todos los programas. En un sistema segmentado, la biblioteca gráfica se puede colocar en un segmento y compartirse entre varios procesos, sin necesidad de tenerla en el espacio de direcciones de cada proceso.
Aunque también es posible tener bibliotecas compartidas sin los sistemas con paginación pura, es mucho más complejo. De hecho, estos sistemas simulan la segmentación.
2.2.1.- Segmentación pura
La implantación de la segmentación difiere del caso de la paginación en un sentido esencial: las páginas tienen un tamaño fijo y los segmentos no. La figura 14 muestra un ejemplo de memoria física que contiene al principio 5 segmentos. Consideremos que el segmento 1 se elimina y su lugar se ocupa por el segmento 7, que es menor. El área que queda entre el segmento 7 y el 2 es un hueco. Luego, el segmento 4 se reemplaza por el segmento 5 y el segmento 3 es reemplazado por el segmento 6. Después de que el sistema esté en ejecución durante cierto tiempo, la memoria quedará dividida en varios bloques, algunos con segmentos y otros con huecos.
Considerando | Paginación | Segmentación |
¿Necesita saber el programador si está utilizando esta técnica? | No | Sí |
¿Cuántos espacios lineales de direcciones existen? | 1 | Muchos |
¿Puede el espacio total de direcciones exceder el tamaño de la memoria física? | Sí | Sí |
¿Pueden distinguirse los procedimientos y los datos, además de protegerse en forma independiente? | No | Sí |
¿Pueden adecuarse con facilidad las tablas con tamaños fluctuantes? | No | Sí |
¿Se facilita el uso de procedimientos compartidos entre los usuarios? | No | Sí |
¿Para qué se inventó esta técnica? | Para obtener un gran espacio lineal de direcciones sin tener que adquirir más memoria física | Para permitir que los programas y datos fueran separados en espacios independientes de direcciones y poder proporcionar la protección y uso de objetos compartidos |
Fig. 13. Comparación de paginación y segmentación.
Este fenómeno de fragmentación externa o checkboarding, desperdicia la memoria correspondiente a los huecos, pero es fácilmente corregido mediante el uso de la compactación. De esta forma los huecos son unificados, generando así un hueco de tamaño suficiente para albergar algún otro segmento más.

Fig. 14. Desarrollo de fragmentación externa y su corrección mediante compactación.
2.2.2.- Segmentación con paginación: MULTICS
En el sistema MULTICS, una dirección lógica está formada por un número de segmento de 18-bit y un offset de 16 bit. Aunque este esquema crea un espacio de dirección de 34-bit, la sobrecarga en la tabla de segmentos es tolerable; solo se requiere de las suficientes localidades en la tabla de segmentos como haya segmentos, puesto que no debe haber localidades vacías.
Sin embargo, con segmentos de palabras de 64K, es donde cada una consiste de 36 bits, el tamaño promedio de segmento puede ser grande y se podría presentar un problema de fragmentación externa. Aunque no lo fuera, el tiempo de búsqueda para ubicar un segmento, usando primer ajuste o mejor ajuste, puede ser prolongado. Lo que puede causar desperdicio de memoria debido a la fragmentación externa, o desperdicio de tiempo por las largas búsquedas o ambas.
La solución al problema es paginar los segmentos. La paginación elimina la fragmentación externa y convierte el problema de ubicación en algo trivial: cualquier frame desocupado puede ser usado para una página deseada. En MULTICS, cada página consiste de palabras de 1K. En consecuencia, el offset del segmento (16 bits) es dividido en un número de página de 6 bit y un offset de página de 10 bit. El número de página se indexa en la tabla de páginas para obtener el número de frame. Finalmente, el número de frame es combinado con el offset de página para formar una dirección física. El esquema de esto se muestra en la figura 15.

Fig. 15. Segmentación paginada en el GE 645 (MULTICS)
Ahora se debe de tener una tabla de páginas individual para cada segmento. Sin embargo, dado que cada segmento está limitado en tamaño por su ubicación en la tabla de segmentos, la tabla de páginas no tiene que ser de tamaño completo, solo requiere de los espacios que son realmente necesarios.
Al igual que en la paginación, la última página de cada segmento, por lo general no estará totalmente llena. En consecuencia, se tiene, en promedio, una fragmentación interna de media página por segmento.
2.2.3.- Segmentación con paginación: Intel 386
El sistema operativo IBM OS/2 de 32 bits es un sistema operativo que corre con las arquitecturas del procesador Intel 386 y 486. El 386 una la segmentación con paginación para su manejo de memoria. El número máximo de segmentos por proceso es de 16K y cada segmento puede llegar a ser de hasta 4 gigabytes. El tamaño de página es de 4K.

Fig. 16. Traducción de dirección en el Intel 80386
El espacio de direcciones lógicas está dividido en dos particiones. La primera partición consiste en segmentos de hasta 8K los cuales son privados para ese proceso. La segunda partición también consiste en segmentos de hasta 8K, los cuales son compartidos entre todos los procesos. La información de la primera partición es guardada en la tabla descriptora local (LDT – Local Descriptor Table), y la de la segunda partición es guardada en la tabla descriptora global (GDT – Global Descriptor Table). Cada registro de las tablas LDT y GDT consiste de 8 bytes con información detallada sobre un segmento en particular incluyendo la ubicación base y longitud del segmento.
Cada segmento es paginado, y cada página es de 4K. Una tabla de páginas puede entonces consistir de hasta un millón de registros. Dado que cada registro consiste de 4 bytes, cada proceso puede llegar a necesitar hasta 4 megabytes de espacio de direcciones física para la tabla de páginas únicamente. Claro está que no sería conveniente alojar la tabla de páginas contigua en la memoria principal. La solución que es implementada en el esquema para el 386, es usar un esquema de paginación de dos niveles. La dirección lineal es dividida en un número de página consistente de 20 bits y un offset de página de 12 bits. Siendo que se pagina a la tabla de páginas, el número de páginas es a su vez dividido en un apuntador para el directorio de páginas de 10 bit y en un apuntador para la tabla de páginas de 10 bit. La transición de la dirección se puede apreciar en más detalle en la figura 16.
Referencias Bibliográficas:
"Sistemas Operativos Modernos" Andrew S. Tanenbaum. 1993. Prentice Hall.
"Sistemas Operativos" William Stallings. 1997 Prentice Hall.
"Sistemas Operativos" Deitel
"Operating System Concepts" Abraham Silberscatz y Peter B. Galvin. 1994 Addison-Wesley.
Monografía realizada para la materia de Sistemas Operativos I a cargo de la profesora Patricia Parroquín por Ricardo Trejo Ramírez. rtrejo@hotmail.com, rctrejo@prodigy.net.mx
Universidad Autónoma de Ciudad Juárez.
Autor:
Ricardo Trejo Ramírez
 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |