 Página anterior Página anterior | Voltar ao início do trabalho | Página seguinte  |
Através deste estudo, pretende-se explorar melhor o tema, de forma a sintetizar o que autores tanto brasileiros quanto estrangeiros falam do assunto, visando assim dar uma melhor noção sobre os clusters de alto desempenho e assuntos correlatos.
OBJETIVOS
Geral
Conhecer as características, arquitetura, funcionamento, principais tipos e aplicações dos Clusters computacionais de alto desempenho.
Específicos
Conhecer quais são as arquiteturas computacionais de alto desempenho existentes;
Identificar as possíveis alternativas existentes em relação aos supercomputadores de alto desempenho utilizados em ambientes geograficamente próximos;
Levantar informações sobre os clusters de computadores;
Conhecer a respeito dos clusters computacionais de alto desempenho.
DELIMITAÇAO DO TRABALHO
Tratar de uma forma geral sobre as principais arquiteturas de alto desempenho, dando enfoque aos clusters computacionais de alto desempenho, de forma a caracterizá-lo, descrever seu funcionamento básico, as principais implementações, bem como os principais ambientes de programação paralela para este tipo de ambiente computacional.
METODOLOGIA DE PESQUISA
A pesquisa será do tipo exploratória, e será desenvolvida por meio de análise bibliográfica.
Com a evolução acelerada das tecnologias e a maior dependência dessas em nosso dia-a-dia, os computadores vêm sendo cada mais vez mais utilizados nas mais diversas tarefas, com o principal objetivo de solucionar problemas da melhor forma e no menor tempo possível. Com isso, o poder computacional das máquinas vêm crescendo cada vez mais, na tentativa de acompanhar as demandas que crescem de forma exponencial com o passar dos anos.
Segundo Alves (2002), na década de 50, considerado a época de início da era computacional, surgiu a primeira geração de computadores, onde foi estabelecido o modelo computacional chamado "modelo de Von Neumann", no qual seria a base de toda era computacional subsequente. Esse modelo era composto basicamente de um processador, memória e dispositivos de entrada e saída de dados, onde o processador atua na execução das instruções de forma sequencial previamente estabelecida.
Para a época, essa arquitetura era mais do suficiente, porém com a evolução da humanidade e o consequente aumento da dependência com a computação principalmente por parte da ciência, esses computadores se tornaram obsoletas e novas tecnologias e arquiteturas tiverem que ser desenvolvidas em um curto período de tempo para atender a crescente demanda. Dentre as melhorias, fez-se necessário o aprimoramento da velocidade dos dispositivos de entrada e saída, velocidade do processador e barramentos, bem como a execução de instruções em paralelo e não mais da forma sequencial.
De acordo com Dantas (2005), um dos fundadores da Intel, Gordon Moore, fez uma previsão de que para cada período de dezoito meses, os sistemas dobrariam de velocidade/desempenho. E de fato, esta previsão se concretizou por muitos anos, sendo que em alguns anos específicos essa previsão foi até excedida.
Segundo Alves (2002), a evolução dos dispositivos foram acontecendo de forma gradativa até que nos anos 80 houve um grande salto na era da computação, com o surgimento dos circuitos integrados de larga escala de integração, os chamados chips VLSI (Very Large Scale Integration). Por mais que que o hardware evoluísse, de forma a conquistar maiores velocidades de processamento e comunicação, sempre havia um fator limitante: o limite tecnológico da época. Devido a isso, desde os primórdios da era de computação já era perceptível pelos cientistas que o uso do processamento paralelo seria fundamental. Historicamente, o uso do paralelismo teve inicio pelo hardware, proporcionamento grandes mudanças nas arquiteturas, que foram evoluindo com o passar dos anos.
Com o barateamento na produção e preço final dos componentes de hardware de um computador com o uso dos chips VLSI, o desenvolvimento de equipamentos cada vez menores, menos custosos e mais velozes foi se tornando realidade. Nesta época, as arquiteturas paralelas e sistemas distribuídos foram surgindo com força total, visando alcançar um poder de processamento jamais vistos anteriormente, de forma a contornar as limitações tecnológicas de hardware.
Com a maior acessibilidade a computadores mais potentes e baratos, tornou-se viável o uso de dois ou mais processadores em computadores paralelos. Também passou a ser interessante, graças também ao surgimento e amadurecimento das redes de computadores, o uso de sistemas distribuídos. Os sistemas distribuídos constituem-se basicamente no uso de vários computadores interligados por uma rede de forma a criar uma imagem única de sistema com uma maior capacidade de processamento. A partir de então, as redes evoluíram cada vez mais, ficando cada vez mais rápidas e estáveis, permitindo assim uma maior eficácia no uso de sistemas distribuídos, sendo essa uma opção de menor custo e maior flexibilidade do que as arquiteturas paralelas. (ALVES, 2002)
Um conceito que é empregado de forma genérica tanto nas arquiteturas paralelas quanto nos sistemas distribuídos, é o termo "Divisão e conquista", que segundo Wikipedia (2010), consiste em dividir um problema maior em problemas menores, onde esses são resolvidos separadamente e após a conclusão de cada um, obtém-se o resultado do problema maior através da combinação dos resultados de todos os problemas menores.
Aplicando o conceito acima, é como se as partes menores de um problema fossem distribuídos entre os diversos processadores de um arquitetura paralela ou então distribuídos entre os diversos computadores (também chamados de "nós") constituintes de um sistema distribuído.
CLASSIFICAÇAO
Segundo Weber (2003), até antes da década de 70, os tipos de arquiteturas e uso dos computadores eram tão restritos que não havia necessidade de seu detalhamento e classificação. Porém com o passar dos anos, a humanidade teve um grande salto no desenvolvimento de computadores e na disseminação do seu uso, surgindo assim diversos tipos e configurações. A partir de então, a categorização das arquiteturas tornou-se necessária, surgindo assim diversas classificações diferentes elaboradas por pesquisadores e cientistas.
Dantas (2005) afirma que dentre as diversas propostas de classificação das arquiteturas de computadores, a mais aceita no mundo da computação é a conhecida taxonomia de Flynn. Esta classificação, apesar de ter sido proposta a mais de 30 anos atrás, até hoje ainda é válida, pois foi construída levando-se em conta o número de instruções que são executadas em paralelo pelo processador confrontado com o conjunto de dados nos quais as instruções são enviadas. A partir de então, foram criadas quatro categorias:
Arquitetura SISD (Single Instruction Single Data) – É a categoria mais simples das quatro, onde o fluxo de processamento e de dados é sequencial, já que uma única instrução é executada por vez para cada dado enviado. (ALVES, 2002)
Os computadores pessoais com um processador uniprocessado se encaixam nessa categoria. Um outro exemplo de arquitetura SISD e seu funcionamento é citado por Tanenbaum (1992, p. 27):
A máquina tradicional de von Neumann é SISD. Ela tem apenas um fluxo de instruções (i. É, um programa), executado por uma única CPU, e uma memória contendo seus dados. A primeira instrução é buscada da memória e então executada. A seguir, a segunda instrução é buscada e executada.
Arquitetura MISD (Multiple Instruction Single Data) – São os computadores que conseguem executar diversas instruções em paralelo sob um mesmo dado. Segundo Dantas (2005), não se tem conhecimento de alguma implementação dessa arquitetura, sendo apenas um modelo teórico de classificação.
Arquitetura SIMD (Single Instruction Multiple Data) – Segundo Tanenbaum (1992), as máquinas SIMD funcionam através do processamento de diversos conjuntos de dados em paralelo. Um exemplo de aplicação desse tipo de computador seria na previsão do tempo, onde os cálculos de uma média de temperatura são feitas através de diversos dados diferentes, organizados em um array de dados.
Exemplo de computadores com esta arquitetura são as máquinas ILLIAC IV (Universidade de Illinois), Thinking Machine CM-2 e MASPAR MP-1216. Máquinas tais como NEC SX e Cray T90 são modelos de máquinas vetoriais que têm um modelo conceitual semelhante às arquiteturas SIMD, mas com a vantagem de poderem realizar o processamento sob parte dos elementos. (DANTAS, 2005, p. 18)
Arquitetura MIMD (Multiple Instruction Multiple Data) – Essa é a categoria que engloba uma variedade de processadores paralelos existentes no mercado. Nesse modelo, cada CPU é independente, executando tarefas e instruções diferentes de forma totalmente paralela.
Existem alguns exemplos dessa arquitetura, como os "[...] computadores paralelos da linha SP da IBM, Intel Paragon, Thinking Machines CM-5 e configurações distribuídas de clusters de computadores" (DANTAS, 2005, p. 18).
Nessa classificação, de fato ocorre o paralelismo. Além dos computadores com diversos processadores, os sistemas distribuídos também fazem parte dessa categoria.
Vale ressaltar que, de acordo com Dantas (2005), os computadores de arquitetura MIMD possuem duas classificações distintas, feitas de acordo como a interligação dos processadores e memórias ocorrem. São elas: os multiprocessadores e os multicomputadores.
De acordo com Tanenbaum (1992), os multiprocessadores são arquiteturas MIMD constituídos por vários processadores que compartilham a memória principal, também denominados sistemas fortemente acoplados. Um exemplo básico desse sistema são os computadores servidores de alta capacidade de processamento que possuem dezenas ou até centenas de processadores interligados por um barramento de alta velocidade na própria placa-mãe, onde a memória principal (RAM) é compartilhada.
Já os multicomputadores se diferenciam pelo fato de não compartilharem a memória principal, de forma que cada processador possui sua própria memória. Estes são chamados de sistemas fracamente acoplados, onde a comunicação entre os processos executados em cada um dos processadores é feita através de troca de mensagens através de uma rede de conexão de dados. Um exemplo típico de multicomputadores são os clusters computacionais. Estes são constituídos de diversos computadores independentes interligados por uma rede local de alta velocidade (que seria o barramento do sistema) onde esses computadores atuam em conjunto de forma a criar a imagem de um único super computador.
ARQUITETURAS DE ALTO DESEMPENHO
Na seção anterior, foi abordada uma classificação clássica das arquiteturas computacionais, com explanação geral sobre as categorias de arquiteturas existentes. Nesta seção, serão abordadas algumas arquiteturas específicas de sistemas multiprocessadores e multicomputadores que são mais comumente utilizadas em diversos ambientes organizacionais onde o maior poder de processamento é indispensável.
Symmetric Multiprocessors (SMP)
De acordo com Pitanga (2003), os sistemas de multiprocessadores simétricos podem ser constituídos de dois e até 64 processadores, sendo classificados como um sistema fortemente acoplado, já que a memória principal é compartilhada entre os processadores. Dantas (2005) afirma que os processadores são consideradores simétricos porque todos eles tem o mesmo custo de acesso à memória e a qualquer dispositivo de entrada e saída do sistema.
A configuração SMP é extremamente popular, existindo diversas implementações comerciais dessa arquitetura, fabricados por grandes corporações como a IBM, DELL e HP. Esses computadores são utilizados em aplicações de até médio porte, como por exemplo servidores de banco de dados, servidores web em geral e outros tipos de aplicações com uma elevada carga de processamento.
Por se tratar de um sistema fortemente acoplado, estes sistemas não são facilmente escaláveis, pois seu crescimento ocorre de forma vertical, ou seja, para aumentar o poder computacional é necessário o acréscimo de novos processadores, onde todos estes se mantém concentrados num mesmo computador, com uma interconexão por barramento. Para o aumento da quantidade de processadores do sistema, acabaram surgindo diversos empecilhos, como por exemplo a limitação de processadores suportados pela placa-mãe e principalmente pelo aumento considerável de colisão de acesso à memória principal. Além disto, existe a limitação da largura de banda do barramento de interconexão, que é de tamanho fixo.
Alguns fabricantes criaram uma saída para contornar, em partes, estes dois problemas: a partir do total de processadores do sistema, dividiram e criaram grupos menores de processores. Cada agrupamento se situa numa placa específica contendo memória local e cache, bem como uma memória global. E assim cada uma dessas placas compostas de diversos processadores e memória global são agrupados numa placa mãe especial de forma a manter o sistema como um SMP "fragmentado", garantindo assim um acesso uniforme a memória global do sistema.
Massively Parallel Processors (MPP)
Os sistemas computacionais com processadores massivamente paralelos são consideradas arquiteturas fracamente acopladas, geralmente se encaixando na categoria dos multicomputadores. Vale ressaltar que um sistema MPP também pode ser constituído por uma combinação de multiprocessadores, como se cada processador fosse um nó de um ambiente de multicomputadores. (DANTAS, 2005).
De acordo com Pitanga (2003), o MPP pode ser descrito como um sistema que efetua processamento paralelo com uso de memória compartilhada e centralizada, sendo composta de até centenas de nós interligados por uma rede de alta velocidade (através de hubs/switches por exemplo), onde cada um desses nós poderm ser computadores comuns com um ou mais processadores e memória principal.
Além disso, Dantas (2005) afirma que cada um dos nós tem como característica o fato de possuir cópia independente do sistema operacional, onde os processos e aplicações são executadas localmente e se comunicam com processos de outros nós através de troca de mensagens através de uma rede de comunicação de dados.
Como é uma arquitetura fracamente acoplada e cada nó do sistema possui memória própria, a escalabilidade do MPP é bem maior do que a das arquiteturas que usam memória compartilhada. Os computadores MPP são bastante utilizados e difundidos, existindo diversas implementações diferentes de fabricantes distintos, conhecidos como Accelerated Strategic Computing Initiative (ASCI). Dentre os exemplos, podemos citar:
HP ASCI Q. Alpha Server SC 45 1.25 Ghz com 8192 processadores;
SGI ASCI Blue Mountain com 6166 processadores;
Intel ASCI Red com 9632 processadores.
Vale ressaltar que Dantas (2005) enfatiza que um elemento muito importante na arquitetura MPP são as redes de interconexão dos nós, efetuada por dispositivos de redes de alta velocidade. Estas redes podem ser implementadas de várias formas, que variam conforme a necessidade e dimensão do projeto. Elas tem como principais parâmetros: a topologia, algoritmo de roteamento, estratégia de comunicação e o controle do flexo entre os nós.
Sistemas distribuídos
Os sistemas distribuídos possuem uma arquitetura com grande escalabilidade, devido a possibilidade de agregação de computadores comuns interligados por redes convencionais. Esses ambientes podem ser constituídos tanto por um conjunto de máquinas homogêneas (todas exatamente com a mesma configuração) quanto de heterogêneas, não havendo qualquer limitação quanto a isso. Devido a esse fator, como cada nó possui sua própria configuração de hardware e software, bem como uma cópia própria do sistema operacional, torna-se possível a formação de diversas configurações de sistemas distribuídos, utilizando-se de configurações SMPs, MPPs e clusters computacionais. (DANTAS, 2005).
Segundo Tanenbaum (2003, p. 2), "[...] em um sistema distribuído, um conjunto de computadores independentes parece ser, para seus usuários, um único sistema coerente. Em geral ele tem um único modelo ou paradigma que apresenta aos usuários".
De acordo com Ribeiro (2005), os sistemas distribuídos foram projetos visando basicamente três objetivos: distribuição de tarefas, compartilhamento de recursos e aumento do poder computacional, sendo todas essas tarefas realizadas através do uso de diversos processadores com memória própria e interligados através de uma rede de computadores (ou linhas de comunicação de dados).
Esse sistema visa o melhoramento na comunicação entre os computadores, no sentido de integrá-los num sentindo amplo, de forma a otimizar o uso dos recursos disponíveis na rede como um todo. Através dos sistemas distribuídos, é possível que um processo ou aplicação seja dividida em partes menores para serem processadas em diferentes nós da rede de forma independente, onde o resultado final é obtido através da junção dessas partes menores, através da comunicação que é feita entre os nós por meio de uma linha de dados. Desta forma, cria-se uma imagem de como se aquela rede de computadores que compõem o sistema distribuído fosse um único sistema de tempo compartilhado, e não simplesmente um agregado de máquinas distintas.
É importante salientar que como nesses sistemas o barramento de comunicação é composta de uma rede de comunicação de dados, esta deve receber atenção especial em relação a alguns aspectos. De acordo com Dantas (2005, p. 31):
Embora a utilização de ambientes distribuídos seja interessante sob o aspecto de utilização de recursos abundantes e na maioria das vezes ociosa nas redes, alguns cuidados devem ser verificados nas fases de projeto e implementação de aplicativos candidatos ao processamento nestas configurações. Aspectos tais como a segurança, o retardo de comunicação, a confiabilidade, a disponibilidade e a compatibilidade de versões de pacotes de software são alguns pontos a serem considerados com cautela.
Segundo Ribeiro (2005), os sistemas distribuídos foram criados para tentar resolver diversos desafios e problemas computacionais, tais como:
Maior confiabilidade do sistema: como os sistemas distribuídos são compostos de computadores independentes, a confiabilidade acaba sendo maior no sistema como um todo, pois caso um ou mais nós do sistemas ficarem inoperantes, o sistema como um todo não ficará inativo.
Flexibilidade estrutural: eles são facilmente adaptáveis a qualquer estrutura de redes computacionais, tanto no sentido organizacional quanto geográfico.
Escalabilidade facilitada: nestes sistemas, o crescimento ocorre de forma horizontal, ou seja, para aumento do poder computacional, basta agregar mais nós (computadores) ao sistema, sendo isso muito mais fácil e simples do que o acréscimo de mais processadores em um computador multiprocessado.
Dependendo da aplicação a ser utilizada, o uso de sistemas distribuídos pode trazer uma grande economia financeira se comparados aos supercomputadores (mainframes por exemplo), devido ao baixo custo dos processadores e computadores convencionais constituintes do sistema. As aplicações e recursos podem ser compartilhados, permitindo assim, o acesso por diversos usuários.
Apesar dessas qualidades, existem algumas relativas desvantagens dos sistemas distribuídos: a pequena variedade de softwares existentes no mercado; alto custo na comunicação e sincronização entre os processadores; e o fato da memória não ser diretamente acessível a todos os processadores do sistema. A segurança também é um fator crítico, já que os dados podem ser acessíveis de diferentes pontos de acesso.
Um exemplo específico e bastante utilizado dos sistemas distribuídos são os clusters de computadores. Eles são agregados de computadores comuns (denominados "nós"), onde esses nós geralmente atuam de forma dedicada com o objetivo de executar no menor tempo possível aplicações específicas em um ambiente computacional com grande demanda de processamento. Uma característica importante dos clusters é que os nós são agrupados em uma área fisicamente restrita, diferentemente dos Grids computacionais, que são um tipo de sistema distribuído caracterizados pela junção de nós geograficamente dispersos.
Por ser um sistema distribuído extremamente eficiente, de baixo custo e relativamente simples de configurar, os clusters de computadores são uma excelente alternativa de baixo custo em relação aos supercomputadores.
De acordo com Pitanga (2003), diversas empresas especializadas na criação e construção de máquinas paralelas de grande porte foram a falência, tendo como principais motivos o custo elevadíssimo, necessidade de mão-de-obra de alto nível de conhecimento/especialização e principalmente pela falta de softwares adequados (linguagens de programação, sistemas operacionais, etc) para serem executados nessas arquiteturas. Nesse cenário, Pitanga (2003, p. 12) afirma que: "Atualmente diversas empresas têm procurado soluções de baixo custo para resolver seus problemas computacionais. A computação em cluster vem ajudar a resolver estes vazios". Os clusters computacionais serão tratados mais detalhadamente no capítulo 3.
ESCALONAMENTO DE TAREFAS
De acordo com Dantas (2005), em ambientes computacionais de um ou mais processadores, seja em sistemas multiprocessadores ou multicomputadores, é fundamental que a atribuição de tarefas aos processadores do sistema seja feita de forma mais eficiente possível, com intuito de reduzir ao máximo o tempo de execução dos processos e dos custos de comunicação, de forma a aproveitar ao máximo dos recursos computacionais disponíveis.
Esses problemas são resolvidos através do escalonamento de tarefas, cujo principal objetivo é encontrar a melhor solução para um determinado problema, através da determinação do melhor processo a ser atribuído para cada processador, de forma a otimizar o desempenho do sistema ao máximo. As estratégias de escalonamento tentam, na maioria das implementações, obter o menor tempo de resposta possível. O escalonamento de tarefas pode ser definido no ramo da computação como uma aplicação que pode atuar em diversos cenários diferentes, sendo uns principais casos no balanceamento de carga entre os nós de um cluster computacional. (PITANGA, 2003).
O balanceamento de carga pode ser definido como um caso especial de escalonamento de tarefas, que se baseia na filosofia que deve ser justo na distribuição de tarefas de acordo com os recursos de hardware do sistema, sendo vantajoso para os usuários deste sistema. Na verdade, a ideia baseia-se nos princípios dos métodos de escalonamento em sistemas monoprocessados multitarefas. (PITANGA, 2003, p. 80).
Segundo Dantas (2005), de acordo com a classificação de escalonamentos mais aceita, elaborada por Casavant e Kuhl, os métodos de escalonamento são divididos em local e global. O primeiro trata do escalonamento de processos através da divisão do tempo (time-slices) de forma a permitir que vários processos sejam executados alternadamente em um único processador. Trata-se do tipo de escalonamento normalmente utilizado pelos sistemas operacionais. Já no escalonamento global, o problema tratado é em qual processador executar um determinado processo, sendo este cenário característico dos sistemas distribuídos. O escalonamento global ainda pode classificado como estático e dinâmico.
No escalonamento global estático, a determinação de quais processos serão executados em quais processadores ocorre antes do início da execução do programa, ou seja, em tempo de compilação. Em tempo de execução do programa, não é possível fazer qualquer tipo de alteração ou ajuste no escalonamento. Nesse método, quando um processo é iniciado num determinado processador, esse rodará até o final de sua execução nesse mesmo processador. Devido a isso, em um sistema onde a carga do programa seja dinâmica, não é recomendável o uso desse tipo de escalonamento, pois como não é possível prever a demanda antes da execução, não será possível fazer um eficaz plano de escalonamento em tempo de compilação.
Já no escalonamento global dinâmico, a distribuição dos processos entre os processadores ou nós é determinada em tempo de execução, ou seja, em tempo de compilação não há necessidade de se saber as necessidades de recursos do programa em questão. Os processos são redistribuídos entre os processadores do sistema durante todo o tempo de execução, através de um ou mais critérios determinados pelo sistema. Basicamente esse tipo de escalonamento realiza o balanceamento de carga entre os processadores constituintes do sistema, de forma a melhorar ao máximo o desempenho das aplicações, otimizando o uso de todo potencial disponível. Devido a essas características, esse tipo de escalonamento é também conhecimento como métodos de balanceamento de carga (Load Balancing - LB) e são muito utilizados em sistemas distribuídos, inclusive nos clusters computacionais.
Ainda em relação ao escalonamento global dinâmico, esse ainda é dividido em dois grupos: distribuídos e não-distribuídos. No primeiro, o algoritmo do programa é executado em todos os nós do sistema. Já no segundo tipo, o escalonamento funciona como um sistema mestre/escravo, de forma que um nó (denominado de "nó mestre" ou "nó controlador") fica responsável por coordenar o escalonamento por todo o sistema e os demais nós (denominados de "nós escravos") apenas executam as instruções que o nó mestre determinar.
DEFINIÇAO
De uma forma geral, quando são utilizados dois ou mais computadores conjuntamente e geograficamente próximos (geralmente em uma mesma sala ou prédio) para resolver algum problema, pode-se dizer que este cenário representa um cluster, palavra que vêm do inglês e significa agrupamento ou agregado. Os clusters de computadores ou simplesmente clustering ou clusters possuem diversas implementações diferentes, com uso de variadas tecnologias para diversos fins. (ALVES, 2002).
Segundo Pitanga (2003), os clusters são constituídos de diversos computadores, chamados de nós, nodos ou nodes, de forma a criar aos usuários a imagem de um sistema único (SSI – Single System Image) que responde a eles, criando a ilusão de que existe apenas um recurso computacional único, como uma espécie de super computador virtual. Desta forma, todos os processos de sincronização, comunicação e distribuição de tarefas, troca de mensagens entre os nós, uso da computação paralela e distribuída e tudo mais que ocorre nos bastidores dos clusters deverão ser transparentes ao usuário.
De acordo com Dantas (2005), devido aos altos custos das máquinas SMP e MPP, as organizações vem utilizando cada vez os clusters computacionais como uma alternativa financeiramente mais eficaz para obtenção de desempenho na execução de diversas aplicações com grande demanda de processamento. Com o aumento dos computadores pessoais nas corporações devido ao seu baixo custo, essa política de agregação de computadores têm se tornado cada vez mais comum. Além da economia financeira, os clusters acabam oferecendo maiores e melhores recursos computacionais aos usuários se comparados com as arquiteturas SMP e MPP. Dantas (2005, p. 147) ainda afirma que "As configurações, conhecidas como clusters computacionais, têm como seu maior objetivo a agregação de recursos computacionais para disponibilizá-los para a melhoria de aplicações".
Apesar dos clusters não serem a solução para todos os problemas computacionais existentes, esses ajudam as organizações a resolverem uma boa parte dos problemas que envolvem grande demanda de processamento, pois eles tentam maximizar o uso dos recursos existentes. Apesar de nem todas os programas poderem ser executados num cluster, uma grande gama de aplicações podem se beneficiar dessa tecnologia. Outro ponto forte é que eles podem ser facilmente projetados levando-se em consideração a escalabilidade, no qual teoricamente infinitos nós podem ser agregados ao sistema na medida em que a demanda aumentar, distribuindo assim a carga de processamento entre os diversos computadores constituintes do agregado. (BOOKMAN, 2003).
De acordo com Pitanga (2003), existem diversas características fundamentais para a implementação de uma plataforma de clusters, tais como:
Distribuição de carga, ou seja, a divisão de uma tarefa em porções menores, distribuindo-as entre os diversos nós do agregado;
Elevação da confiança, através da redundância dos dados e planos de contingência do sistema, de forma que o sistema como um todo não pare caso um ou mais nós fiquem inoperantes;
Performance, sendo aprimorada através do uso de algoritmos de escalonamentos eficazes para o determinado problema, de forma a explorar ao máximo os recursos computacionais existentes em cada nó do cluster.
Para a formação de um cluster de computadores, basicamente os seguintes componentes são necessários:
Computadores de alta performance – estações de trabalho ou máquinas SMP's. Dependendo do tipo de cluster, um nó atuará como controlador e os demais como escravos, sendo o primeiro responsável por coordenar e distribuir tarefas bem como monitorar a atuação de cada um dos nós escravos;
Redes de alta performance, fazendo parte as placas de interface de rede para cada nó (interfaces gigabit ethernet, Myrinet e SCI), comutadores de pacotes (switches por exemplo) e os protocolos e serviços de comunicação de alto desempenho;
Sistemas operacionais, podendo ser específicos para ambientes de clusters ou sistemas operacionais comuns;
Criação de uma imagem única e disponibilidade do sistema;
Aplicações e subsistemas de manutenção, gerenciamento do agrupamento de computadores e sistemas de arquivos paralelos;
Bibliotecas de passagem de mensagens, como o PVM e MPI;
Aplicações paralelas.
Devido as inúmeras vantagens dos clusters computacionais (principalmente pela alta flexibilidade de expansão, uso de computares comuns e a relativa facilidade de configuração e uso), ele se tornou um destaque dentre os sistemas distribuídos, tendo diversas implementações diferentes desenvolvidas visando ou a alta performance computacional e/ou balanceamento de carga e/ou a alta disponibilidade. Eles vêm sendo utilizados em diversas organizações, que vão desde pequenas empresas e faculdades de exatas e computação, até em laboratórios de engenharia genética e atômica.
Organizações como a National Oceanic e Atmospheric Administration são capazes de usar clusters para prever tendências de condições de tempo potencialmente perigosas. O pessoal de Lawrence Livermore Lab usa computadores agrupados para simular uma explosão nuclear completa, sem dano a ninguém [...]" (BOOKMAN, 2003, p. 4).
COMPUTAÇAO PARALELA E DISTRIBUÍDA
Segundo Sloan (2004), existem basicamente três abordagens para aperfeiçoar a performance na computação: usar um algoritmo melhor, usar um computador mais rápido, ou dividir o problema entre diversos computadores. Porém tanto a primeira quanto a segunda abordagem possuem limitações quanto ao ganho máximo de performance que na terceira abordagem não ocorre: um algoritmo poderá ser aperfeiçoado até chegar a um ponto que não há mais o que se fazer; já a segunda abordagem possui um limite financeiro ou tecnológico, para a compra de um computador mais potente.
Na terceira abordagem, é tratado o conceito de computação paralela ou simplesmente paralelismo, onde a execução de tarefas ocorre simultaneamente. Isso até pode ser feito por um único computador (com diversos núcleos por exemplo), porém novamente caímos nas limitações da segunda abordagem. A saída para essa limitação está na divisão das tarefas por diversos computadores interligados por uma rede, de forma que cada nó resolverá parte do problema, todas funcionando simultaneamente, ocorrendo assim o paralelismo. Este cenário apresentado refere-se um típico cluster de computadores.
A computação paralela pode ser então caracterizada, segundo (BOOKMAN, 2003, p. 12), como "[...] a submissão de trabalhos ou processos em mais do que um processador [...]" de forma paralela e simultânea. Os clusters computacionais trabalham de forma a dividir e distribuir o trabalho entre os diversos nós do agregado. Assim, o desempenho na execução de uma tarefa por diversos computadores tende a ser muito mais eficiente do que a execução da mesma tarefa em um único computador. Porém, não quer dizer que a velocidade de execução é proporcional a quantidade de nós disponíveis no cluster. Por exemplo, uma instrução que é executada num agrupamento constituído de 20 computadores não quer dizer que necessariamente será 20 vezes mais rápida se comparado ao tempo de execução da mesma instrução em um único computador, mas com certeza será bem maior.
Ainda de acordo com Bookman (2003), para que um programa se beneficie dos recursos da computação paralela, diversos requisitos devem ser levados em conta, tais como: código do programa projetado para ser executado em ambientes paralelos, bem como otimizado para que ser quebrado e distribuído entre diversos processadores ou computadores. Se essas otimizações não foram observadas, pode ocorrer até de um programa rodar mais rapidamente em um único computador do que se fosse executado em diversos nós de um cluster. A computação paralela foi projetada para executar aplicações que englobam cálculos matemáticos extremamente complexos, como por exemplo na área de simulação de explosões nucleares, computação gráfica, pesquisas científicas e engenharia genética.
De acordo com Sloan (2004), enquanto o termo "computação paralela" é frequentemente usado para se referir aos clusters, porém é mais correto referir-se a eles como um tipo de computação distribuída. Geralmente, o termo "computação paralela" é usado para fazer referência aos computadores fortemente acoplados, e o termo "computação distribuída" é caracterizado pela computação que é espalhada por múltiplas máquinas ou múltiplas localizações diferentes. Apesar disso, ambos os termos podem ser usados corretamente em sistemas multicomputadores: o termo "paralelo" é usado para se referir aos clusters homogêneos, enquanto o termo "computação distribuída" geralmente se refere mais aos clusters heterogêneos.
Segundo Bookman (2003), os termos computação paralela e computação distribuída podem ser confundidas, porém o que diferencia ambas é o fato de que na paralela, os clusters são necessariamente constituídos de nós dedicados (ou seja, de uso exclusivo dos clusters) e geralmente homogêneos. Já na computação distribuída, os dados são espalhados por diversos nós geograficamente distantes ou não, onde esses geralmente são heterogêneos e não são de uso exclusivo para esse fim.
Computação distribuída é a habilidade de executar vários trabalhos através da potência de processamento de ambiente, principalmente heterogêneos. Embora a computação distribuída possa ser facilmente coberta sob sistemas homogêneos, o que diferencia a computação paralela da computação distribuída é que ela não é necessariamente ligada a um tipo de máquina, ou cluster dedicado. (BOOKMAN, 2003, p. 127).
Um exemplo hipotético para a computação distribuída seria a formação de um cluster constituído de computadores comuns de um escritório, onde estes computadores são utilizados pelos funcionários, porém sobram recursos computacionais. O cluster atuará explorando esses recursos ociosos, em paralelo ao uso comum feito pelos funcionários.
Existe também um exemplo prático e real muito conhecido no ramo da Ciência da Computação: o projeto SETI@HOME. De acordo com SETI@HOME (2010), este é um projeto criado com intuito de buscar sinais de vida extraterrestre através da análise de materiais coletados por um gigantesco radiotelescópio. O funcionamento dele é bastante interessante: o internauta baixa o programa deles e instala em seu computador. A partir de então e estando conectado na internet, esse computador passará a atuar como um nó de um grande sistema distribuído geograficamente distante (Grid computacional), gerenciado pela equipe do projeto. Assim, milhares e milhares de computadores (dos mais variados tipos e configurações) do mundo todo estão interligados formando um imenso sistema distribuído, atuando na análise dos milhões de dados captados diariamente pelo radiotelescópio.
Uma observação interessante e esclarecedora é feita por Pitanga (2003), onde cita que a computação paralela objetiva resolver os problemas de uma forma mais rápida; já a computação distribuída não necessariamente visa aumentar o poder de processamento, mas também pode ter outras finalidades, como por exemplo a alta disponibilidade. Diante disto, a computação paralela pode ser considerada como um tipo específico de computação distribuída.
IMAGEM ÚNICA DO SISTEMA
Segundo Pitanga (2003), a imagem única do sistema (Single System Image – SSI) é uma propriedade que visa ocultar toda a estrutura complexa, distribuída e heterogênea de um cluster de computadores aos olhos dos usuários, de forma que o agrupamento seja visto como um único computador. O SSI pode ser implementado tanto por hardware quanto por software e faz com que os usuários tenham uma visão globalizada dos recursos disponíveis, independente da quantidade de nós associados. Ele também faz o papel de garantir que o sistema continue funcionando mesmo que um ou mais nós do sistemas apresentem alguma falha e fiquem inoperantes, bem como assegurar que todos os nós do sistema fiquem ocupados e com os recursos computacionais sendo utilizados, através do gerenciamento de recursos e o escalonamento de tarefas.
Os maiores objetivos do SSI em um sistema de cluster computacional são: criar uma transparência total no gerenciamento dos recursos; garantir um sistema sempre disponível ao usuário; manter a alta escalabilidade de performance. O SSI pode ser dito como uma "ilusão" criada ou por hardware ou por software, de forma a apresentar um conjunto de recursos computacionais como se fossem um só componente.
Pitanga (2003) ainda salienta que o SSI é considerado como uma camada mediadora ( middleware), que atua entre a camada do sistema operacional e a camada do usuário. O middleware é formado por duas subcamadas: infra-estrutura de disponibilidade (AS) e a infra-estrutura de imagem única (SSI). A AS fornece ao cluster serviços relacionados a disponibilidade de dados, tais como rotinas de recuperação e tolerância a falhas e checkpoints. Já a infra-estrutura de SSI, esta presente em todos os sistemas operacionais de todos os nós para implementar a unificação dos recursos. Uma visão geral da camada middleware é demonstrada na figura 1.

O interessante é que o SSI pode ser implementado em diversas camadas. Na camada de hardware, pode ser implementado através do uso de técnicas de SMP ou DEC Memory Channel por exemplo; na camada middleware, criando uma interface entre o software, hardware e o sistema operacional do cluster, sendo esta a abordagem mais utilizada; e na camada adicional do núcleo do sistema operacional de cada um dos nós, como é o caso dos sistemas operacionais baseados em clusters, como o OpenMosix por exemplo, em que possuem o SSI implementado diretamente em seu kernel.
De acordo com Dantas (2005), o uso do SSI na middleware gera uma maior flexibilidade de configuração do cluster, devido a independência que esse cria em relação a qualquer que seja o sistema operacional que está sendo executado em cada um dos nós do agregado, fazendo com que o usuário visualize o ambiente como uma coisa só.
O uso do SSI oferece inúmeras vantagens tanto ao sistema quanto ao usuário, tais como:
Redução de tempo e esforço por parte dos programadores, para criação e execução de aplicações que serão executadas no cluster;
Localização física dos dispositivos totalmente transparente ao usuário, facilitando assim o acesso;
Alta disponibilidade dos serviços;
Redução de danos em casos de erros operacionais;
Criação de um modelo de processos globalizados;
Facilidade na localização de todos os recursos;
Facilidade e maior agilidade na interação do usuário com o cluster, através de interfaces mais amigáveis e práticas.
TIPOS DE CLUSTERS
Originalmente, os clusters de computadores eram relacionados diretamente com o termo "computação de alto desempenho", sendo essa basicamente o único tipo existente. Porém, nos dias atuais, com a evolução dos clusters e o surgimento de diferentes tipos de problemas, o termo "cluster" ficou mais amplo, abrangendo além da categoria de alto desempenho, outras duas categorias de clusters: os de alta disponibilidade (High Availability – HA) e os de balanceamento de carga (Load Balancing – LB). (SLOAN, 2004).
Essas três categorias de clusters serão tratados logo a seguir. É importante salientar que podem existir implementações de clusters que combinem mais de um tipo em um único sistema, como por exemplo os agregados que atuam tanto no balanceamento de carga quanto na alta disponibilidade.
Alta disponibilidade
É comum e previsível que qualquer tipo de equipamento, inclusive os computadores, cedo ou tarde possam apresentar falhas tanto de hardware quanto de software. Quando isso ocorre num computador utilizado em casa, geralmente não há necessidade de desespero por parte do usuário, já que não envolve a execução de aplicação crítica. Já quanto tratam-se de computadores de uso crítico, como servidores que executam aplicações fundamentais de uma corporação, as panes provavelmente tirarão sistemas do ar, e dependendo do nível de dependência da empresa com essa disponibilidade, os prejuízos poderão ser milionários ou até poderão jogar a corporação à beira da falência. Por exemplo, imagem se uma empresa de vendas pela internet ficar com seu site fora do ar por algumas horas: isso poderá significar milhares de reais de prejuízo, além de poder manchar o nome da empresa e deixar clientes insatisfeitos.
São nestes e em muitos outros cenários que a alta disponibilidade entra em cena. Através de redundância tanto de hardware quanto de software, a alta disponibilidade de dados e serviços são garantidos.
De acordo com Pitanga (2003), a necessidade de alta disponibilidade está diretamente ligada a crescente dependência da sociedade com os computadores, tento eles um papel crítico principalmente para empresas. Para atender estes e outros tipos de cenários críticos que os clusters computacionais de alta disponibilidade foram criados.
Basicamente, os clusters de alta disponibilidade tem como maior objetivo manter disponível os serviços oferecidos por um sistema computacional, através da redundância tanto de hardware e software, atingidas através da replicação dos dados e serviços através dos diversos nós de um cluster. No agrupamento, todos os nós atuam fornecendo os mesmos serviços e o dados são replicados e mantidos atualizados em todos eles. Além disso, cada nó fica monitorando o outro e caso algum falhe, o outro assume automaticamente todos os serviços prestados de forma a evitar a interrupção.
Um exemplo simples desse tipo de cluster é ilustrado na figura 2, onde hipoteticamente o cluster demonstrado seja usado para prover serviços web, armazenando a página de uma empresa de vendas online. O agregado é composto de nós idênticos, ambos executando os mesmos serviços e mantendo os dados sincronizados um com o outro e no banco de dados. Um deles atuará como o nó principal, atendendo as requisições dos clientes que estiverem acessando o site. Além disso, esse nó sempre replicará todas as alterações ao nó secundário, mantendo-o sempre preparado para assumir seu lugar. O nó secundário, além de se manter sincronizado e em estado de espera (standby), ficará monitorando os serviços e o funcionamento do nó principal. Caso o nó principal apresentar falhas de hardware e/ou de software, o secundário automaticamente assumirá o endereço IP e todos os serviços, de forma que o usuário final não perceba nenhuma mudança e tudo continue funcionando perfeitamente para os clientes, sem interrupção dos serviços.

Nesses ambientes de alta disponibilidade, como ocorre a replicação de dados entre todos os nós, de forma a mantê-los sincronizados e preparados para assumir os serviços caso o nó atuante falhe, pode acabar gerando perdas de performance de processamento. Porém isto é perfeitamente aceitável, já que o principal foco de um cluster de alta disponibilidade é manter os serviços funcionando ininterruptamente. Outo ponto importante a ser citado é que geralmente esses tipos de clusters são homogêneos, ou seja, os nós tanto do ponto de vista de hardware quanto de software são idênticos.
Balanceamento de carga
Segundo Sloan (2004), um cluster de balanceamento de carga basicamente tem o objetivo de prover uma melhor performance, distribuindo diversos trabalhos através de múltiplos computadores do agregado. Por exemplo, quando um servidor web é implementado neste tipo de cluster, cada usuário de internet que requisita uma página deste servidor será redirecionado a um dos nós disponíveis. Desta forma, será evitado que um único computador atenda todas as requisições, evitando dessa forma o sobrecarregamento e consequente risco de falhas no sistema.
Com o espantoso crescimento da informatização em todas as corporações e o uso cada vez mais comum da internet para fornecimento de serviços onlines, os clusters de balanceamento de carga vêm sendo amplamente utilizados, pois são uma solução inteligente e eficaz para contornar os sérios problemas gerados pelo aumento exponencial da demanda de acessos a sistemas onlines.
Equilíbrio de carga refere-se ao método onde os dados são distribuídos através de mais do que um servidor. Quase qualquer aplicativo paralelo ou distribuído pode se beneficiar do equilíbrio de carga. Tipicamente, os servidores Web são mais proveitosos e, portanto, o aplicativo mais utilizado de equilíbrio de carga. (BOOKMAN, 2003, p. 10)
De acordo com Alves (2002), um exemplo típico de uso desse tipo de cluster são os sites de busca como o Google. Estes portais de busca possuem uma quantidade de acessos e requisições de busca extremamente altos, chegando a atingir a demanda de milhões de requisições por segundo. Um único computador, por mais potente que fosse, seria incapaz de atender todas essas requisições sem comprometer a velocidade de resposta às requisições. Já num cluster de balanceamento de carga, as requisições vão sendo distribuídas entre centenas e milhares de nós, mantendo assim a qualidade no acesso e na velocidade de resposta das requisições, suprindo toda a demanda e o melhor de tudo: tudo isso ocorrendo de forma transparente ao usuário final.
O balanceamento de carga vêm sendo a solução para muitos problemas oriundos do crescimento explosivo da internet no mundo, sendo parte integrante e vital em qualquer projeto de comércio eletrônico, hospedagem de sites, sites de grande fluxos, dentre outros que recebam grandes quantidades de acessos e requisições simultâneas.
Segundo Pitanga (2003), num cluster de balanceamento de carga deverá haver um nó responsável por controlar e realizar, de fato, o balanceamento de carga entre os diversos servidores constituintes do agrupamento. Geralmente chamado de nó mestre ou nó controlador, este nó "balanceador" deverá receber todas as requisições dos clientes e repassá-los para os demais nós do cluster. Desta forma, além prover uma distribuição equilibrada de requisições entre os nós e evitar que sejam repassadas para algum nó que tenha acabado de apresentam algum tipo de falha, o nó mestre fará com que o cliente tenha a visão de um serviço que seja provido por um único computador.
Existem diversos softwares para implementação de balanceamento de carga, como por exemplo o Virtual Server e o Turbo Cluster. Também é possível que se tenha mais de um nó controlador, para garantir uma maior disponibilidade do sistema, caso o nó controlador primário venha a apresentar falhas.
Alto desempenho
De acordo com Sloan (2004), tradicionalmente o cluster de alto desempenho foi o primeiro tipo de cluster criado, cujo objetivo fundamental é o de realizar processamento em paralelo para que as instruções sejam executadas o mais rápido possível. Diversas implementações foram criadas e sendo utilizadas em vários meios, que vão desde ambientes de cálculos relativamente mais simples como a previsão do tempo, até em computação mais massiva e complexa, como modelagem astronômica e dinâmica molecular. Também referenciado como clusters HPC (High Performance Computing), este tipo de agregado computacional acabou criando uma nova abordagem no mundo da computação, estabelecendo um modelo alternativo de baixo custo e extremamente viável para o fornecimento de alto poder computacional.
Segundo Alves (2002), os clusters de alto desempenho são uma solução alternativa para obtenção de processamento de alta performance na resolução de problemas computacionais por meio de aplicações executadas em paralelo, tudo isso a um preço bem mais baixo se comparado a um supercomputador (mainframes por exemplo) com um poder de processamento equivalente.
Um cluster de alto desempenho é uma espécie de sistema que realiza processamento paralelo ou distribuído através de diversos nós que constituem o agregado computacional, onde esses estão interconectados e trabalhando juntos, de forma a criar a imagem de um único recurso computacional (SSI), fornecendo características e vantagens comparáveis aos dos supercomputadores.
O capítulo 4 tratará mais detalhadamente sobre esse tipo de cluster, detalhando suas características, áreas de aplicações, vantagens, funcionamento básico e os principais exemplos de implementações.
REDES DE INTERCONEXAO
As redes de computadores foram criadas e aperfeiçoadas com intuito de atender a eminente necessidade de compartilhamento dos recursos computacionais e dados em ambientes corporativos. Um dos primeiros sistemas comerciais de interconexão de computadores começou a ser utilizado nos Estados Unidos em 1964. Essa rede utilizava tecnologia que era patenteada e fornecida por uma única empresa. Já em 1970, surgiram as primeiras iniciativas de criação e implantação de redes computacionais abertas desenvolvidas por diversos fabricantes, surgindo assim um conjunto de protocolos livres de patente e uso, desenvolvidos por grandes empresas tais como a Xerox e a Intel. A partir daí as redes de computadores foram se popularizando cada vez mais, tornando-se cada vez mais rápidas, baratas e confiáveis. (PINHEIRO, 2003).
A partir dessa popularização, barateamento e amadurecimento das tecnologias de interconexão de redes, os clusters computacionais tornaram-se mais interessantes e viáveis, passando a serem amplamente utilizados. Tanenbaum (2003) ressalta que muitas literaturas fazem confusão entre o termo "redes de computadores" e "sistemas distribuídos", como os clusters. Ele afirma que num sistema distribuído, um conjunto de computadores independentes atuam de forma a criar, do ponto de vista do usuário, a imagem de um sistema único e coerente. Já uma rede de computadores em si não possui essa coerência, ficando os usuários expostos diretamente às máquinas reais da rede, sem que haja a impressão de um sistema único.
Para os clusters computacionais, a rede de interconexão é um item fundamental para sua existência e funcionamento, já que atuam como o barramento de comunicação desse tipo de arquitetura. Através dessas redes, os nós podem comunicar entre si, além de possibilitarem a criação de uma imagem única do sistema. A maneira como essas redes são implementadas podem variar de um sistema para o outro, devido a existência de várias tecnologias de redes distintas.
De acordo com Dantas (2005), o meio como os nós são interconectados são muito importantes e basicamente se classificam em três grupos: compartilhada, ponto-a-ponto e híbrida. Cada uma desses tipos de rede ainda são subdivididas conforme mostra a figura 3.

Quanto a primeira categoria, rede compartilhada, ela é bastante difundida e utilizada em redes locais, principalmente pelo fato de ter um bom desempenho e custos relativamente baixos em relação a outros tipos de redes. Nela, os nós da rede se comunicam através de um meio comum compartilhado, que é controlado por um sistema de protocolos que podem ser do tipo ordenado ou não-ordenado. Os hubs e os switches (baseados nos protocolos Ethernet e Fast-Ethernet) são exemplos de dispositivos que promovem esse tipo de redes de interconexão e são amplamente utilizadas em redes locais e em diversos tipos clusters, como os clusters Beowulf e outros da categoria dos clusters de alto desempenho.
Já na rede ponto-a-ponto, cada nó é interligado com outro através de um enlace dedicado, ou seja, teoricamente pode-se deduzir que todos os nós da rede podem se comunicar simultaneamente em um determinado momento, já que o meio de comunicação entre eles não é compartilhado.
Ainda de acordo com Dantas (2005), a rede ponto-a-ponto ainda é subdividida em direta e indireta. Na direta, os elementos da rede possuem ligação estática entre si, como por exemplo nas redes do tipo malha, árvore e hipercubo. Na rede indireta, a interligação é feita de forma dinâmica, tendo como exemplo as redes de barramento cruzado e as de múltiplos estágios. As redes ponto-a-ponto, apesar de possuírem como vantagem a maior facilidade de comunicação, elas não são tão populares quanto as redes do tipo compartilhada, principalmente devido aos custos mais elevados.
No último tipo de interconexão de redes, a híbrida, existem algumas características semelhantes aos das redes diretas e outras inerentes das redes indiretas. As redes baseadas em agregados e as de barramento hierárquicos são alguns dos exemplos mais comuns desse tipo de rede.
Como pode ser observado, existem diversas topologias de redes para serem usadas nos clusters de computadores, sendo algumas já bastante populares e consolidadas, como a Fast Ethernet e outras ainda em pesquisa e desenvolvimento.
Segundo Alves (2002), as redes de interconexão mais comumente utilizadas nos clusters são as do tipo ponto-a-ponto, como por exemplo as topologias árvore, hipercubo e malha, sendo essa última ilustrada na figura 4.

Como visto, cada tipo de rede de interconexão e suas topologias possuem vantagens e desvantagens, sendo cada uma ideal para uma determinada situação. Por exemplo, a topologia em malha é totalmente conectada, provendo maior velocidade na comunicação, porém possui um custo de implementação muito elevado além de limitações de expansão, não sendo viável para um cluster com muitos nós.
Alves (2002) ainda salienta que para avaliar o desempenho de uma rede de computadores, inclusive a de um cluster, deve-se medir a latência e a largura de banda do meio de comunicação. A latência é o tempo que um dado demora para trafegar de nó da rede para outro, e a largura de banda é a quantidade de bits que os dispositivos de interconexão de redes são capazes de transmitir a cada segundo.
Para um cluster ter um bom desempenho, os programas que serão executados nele deverão ser projetados de forma a utilizarem o mínimo possível do meio de transmissão. Deve-se atingir um equilíbrio entre a quantidade de mensagens transmitidas entre os nós e o tamanho delas, já que grandes quantidades de mensagens pequenas serão afetadas pela latência e poucas mensagens de tamanho grande serão afetadas pela limitação da largura de banda. Alves (2002) reforça que a latência é inversamente proporcional a eficiência do sistema e a largura de banda é diretamente proporcional a eficiência do sistema.
Tecnologias de redes para clusters
Segundo Pitanga (2003), a rede é um dos itens primordiais para que um cluster atinja uma performance eficaz e seja bem sucedido. Por isso a escolha da tecnologia de rede de interconexão que será utilizada num cluster é uma tarefa peculiar e requer muitos cuidados, já que deve haver um bom balanceamento da comunicação entre os nós do agrupamento, conjuntamente com o balanceamento de carga de processamento, evitando assim o desperdício de recursos.
O problema maior são os custos, pois existem tecnologias de rede muito avançadas e rápidas que representam uma boa parte dos gastos no projeto; assim como outras tecnologias bem mais em conta, porém não tão modernas. A questão aqui é que deve-se avaliar qual tecnologia atenderá melhor a demanda, para assim escolher uma tecnologia ideal que atenda todas as necessidades, sem que haja sobra de recursos e consequentemente um gasto maior em tecnologias de rede que não eram necessárias. Como uma das grandes vantagens do uso dos clusters é o seu baixo custo de implementação, o cuidado com a escolha da tecnologia de rede deve ser criteriosa o suficiente para que essa grande vantagem não se extingua.
Com a evolução da computação, da crescente necessidade de comunicação e redes computacionais e também com o desenvolvimento e popularização dos clusters computacionais, diversas pesquisas foram e estão sendo realizadas visando o desenvolvimento de novas tecnologias de rede, objetivando além da redução de custos, o aumento da performance através da redução da latência e do aumento da largura de banda.
Ainda de acordo com Pitanga (2003), existem diversas tecnologias de rede de alto desempenho mais popularmente utilizadas em clusters computacionais, tais como a Fast Ethernet, Gigabit Ethernet, Myrinet e a SCI.
FAST ETHERNET
Esta é a tecnologia de rede mais comumente utilizada em todo mundo em redes locais tanto de pequeno quanto de médio e grande porte. Também é popularmente utilizada nos clusters. De acordo com Tanenbaum (2003), esta tecnologia foi criada como um substituto evolutivo do Ethernet original, pois a necessidade de uma maior largura de banda passou a ser algo indispensável. Como o comitê responsável por essa tecnologia temia que a criação de um novo protocolo pudesse trazer problemas imprevistos, além de problemas de compatibilidade com a Ethernet tradicional, eles resolveram aperfeiçoar o que já existia, criando assim o Fast Ethernet.
Segundo Tanenbaum (2003, p. 302), a ideia básica dessa tecnologia era simples: "[...]manter os antigos formatos de quadros, interfaces e regras de procedimentos, e apenas reduzir o tempo de bit de 100ns para 10ns". Desta forma, conseguiu-se elevar a taxa de transferência de 10Mbits/s para 100Mbits/s.
GIGABIT ETHERNET
Após poucos anos da homologação do padrão Fast Ethernet, o comitê 802 da IEEE respectiva passou a desenvolver um novo padrão. Basicamente a meta era tornar esse novo padrão 10 vezes mais rápido que o seu antecessor, porém sem perder a compatibilidade com seus antecessores. Nesta tecnologia, as conexões passaram a ser exclusivamente no modo ponto-a-ponto e trabalhando a 1000Mbits/s. Outra característica, é que nesse padrão admite-se tanto fiação de cobre (padrão 1000Base-CX com até 25m de cumprimento, e o padrão 100Base-T com até 100 metros de cumprimento) quanto de fibra óptica (padrão 1000Base-SX com cumprimento de até 550 metros, e o padrão 1000Base-LX com cumprimento máximo de 5 mil metros). Nos primeiros anos de lançamento comercial do Gigabit Ethernet, os preços eram bastante elevados, não sendo interessante sua utilização nos clusters. Porém, atualmente os preços caíram muito e praticamente este padrão "enterrou" o seu antecessor, passando a ser amplamente utilizados nos clusters mais recentemente montados. (TANENBAUM, 2003).
MYRINET
Segundo Dantas (2005), a Myrinet é um padrão público e aberto desenvolvido com intuito de prover comunicação eficiente de pacotes, alto desempenho e comutação de dados eficaz. Foi criado principalmente para ser usado na formação de clusters constituídos de nós de diversos tipos, tais como estações de trabalho e servidores.
O uso de tecnologias mais comuns como o Fast Ethernet e Gigabit Ethernet podem ser usados nos clusters de computadores, mas esses dois padrões tem um problema: não fornecem para o cluster, a nível de hardware, características que envolvam tanto a alta disponibilidade quanto a alta performance na transmissão de dados. Os padrões Ethernet's citados são bastante utilizados e atendem muito bem a clusters de pequeno e médio porte, que não atuam em tarefas críticas. Porém já para clusters com alta carga de processamento e também que sejam utilizadas na execução de tarefas críticas, o Myrinet passa a ser muito mais recomendável, apesar dos custos serem mais elevados.
De acordo com Pitanga (2003), o Myrinet possui algumas características peculiares, tais como:
Interfaces de rede trabalhando em full-duplex com velocidade de até 2Gbps/s;
Baixa latência e switches com monitoramento de aplicações que necessitam de alta disponibilidade;
Switches capazes de escalar de dezenas a até milhares de nós, inclusive com a possibilidade de utilizar caminhos alternativos entre cada computador;
Controle de erro, de fluxo e monitoramento contínuo de cada enlace de dados.
Como mencionado anteriormente, os custos desta tecnologia são elevados. Por exemplo, o custo de uma interface de rede Myrinet gira em torno de US$ 700,00 e um switch de 8 portas, mostrado na figura 5, custa em torno de US$ 1.500,00. Esses valores são pelo menos 12 vezes mais elevados do que o harware equivalente no padrão Gigabit Ethernet.

SCALABLE COHERENT INTERFACE (SCI)
De acordo com Pitanga (2003), o SCI é uma tecnologia que foi concluída em 1992, projetada para ser uma interface de alto desempenho. Ela é caracterizada por ser muito rápida, flexível e com protocolo de comutação de pacotes ponto-a-ponto. O interessante dessa tecnologia é que ela é capaz de permitir que a memória seja compartilhada entre processadores e placas do sistema, graças a sua alta velocidade e largura de banda.
O SCI é uma das tecnologias mais utilizadas em sistemas multiprocessadores, pois ele foi feito para evitar que a rede seja o fator limitante na velocidade de comunicação com os barramentos do sistema. Ela é muita utilizada em sistemas multiprocessados desenvolvimentos para o exército e também em aplicações cujos ambientes de computação são massivamente paralelos. O grande segredo por trás dessa tecnologia é o fato de ocorrer o compartilhamento de memória entre os nós processadores e não a realização de troca de mensagens como ocorre nos clusters mais comuns. Dessa forma, um cluster que faz uso dessa tecnologia adota o modelo de memória global compartilhada, como ocorre nos sistemas MPP visto no capítulo anterior.
Essa tecnologia pode funcionar com uma ligação paralela de 16 bits através de uma topologia em anel ou em estrela, onde cada interface é constituída de dois canais de comunicação – um de entrada e outro de saída – com taxas de transferência de até 1000Mbits/s. A ligação pode ser feita por cabos de cobre, com limitação de até 10 metros de distância, ou por fibra óptica, podendo estender-se por até alguns quilômetros usando deste meio. As interfaces SCI mais atuais já conseguem atingir a impressionante marca dos 5.33Gigabits/s.
Pitanga (2003, p. 148) conclui que o SCI é uma das melhores tecnologias existentes nos dias atuais: "Além do alto desempenho, a possibilidade de programação com memória compartilhada gera um enorme atrativo, daí concluímos então que a SCI é uma das mais promissoras tecnologias de comunicação em rede da atualidade".
O cluster de alto desempenho foi o primeiro tipo de cluster criado, sendo por muito tempo referenciado apenas como cluster, até o surgimento dos outros tipos de agregados computacionais.
Segundo Alves (2002, p. 14) "Esta classe da ciência da computação tem como foco o desenvolvimento de supercomputadores [.], algoritmos de processamento paralelo, construção de aplicações paralelas". Alves (2002) ainda afirma que esse tipo de cluster tornou-se uma solução alternativa para corporações e universidades que necessitam de alta performance computacional para resoluções de problemas diversos a um custo bem menor do que os supercomputadores com capacidade de processamento equivalente. Os clusters de alto desempenho são amplamente utilizados e são aplicadas nas mais diversas áreas imagináveis, desde as mais simples, até as mais complexas. Alguns exemplos de áreas de aplicações serão detalhadas na próxima seção.
Além da vantagem relacionada aos custos, outra trata da facilidade de montagem do cluster de alta performance: basta ter disponíveis diversos computadores comuns interconectados por uma rede de alta velocidade, como a Gigabit Ethernet, e alguns softwares instalados para criação de imagem única do sistema e gerenciamento do sistema.
Também chamados de clusters HPC (High Performance Computing), as tarefas nele executados são submetidas a um ambiente de processamento distribuído e paralelo, cujo objetivo primaz é basicamente a execução das instruções no menor tempo possível. Uma grande tarefa é dividida em porções menores, e essas são distribuídas pelos nós do agregado computacional. Cada um desses nós trabalham paralelamente em relação aos demais, devolvendo o resultado para o nó controlador, que por sua vez junta os resultados individuais e gera o resultado global.
De acordo com Pitanga (2003), um cluster de alto desempenho é basicamente constituído de um agrupamento de diversos computadores através de uma rede de dados, onde trabalham conjuntamente de forma a criar um sistema virtualmente homogêneo voltando para execução de processamento paralelo com a finalidade de executar as tarefas no menor tempo possível. Os nós do agregado poderão ser computadores comuns, como estações de trabalho e computadores SMP's, com sistema operacional independente. Mesmo o cluster sendo composto de computadores comuns, esse atua com desempenho igual ou até superior ao dos supercomputadores de memória compartilhada. Os nós também poderão conter mais de um processador (arquiteturas SMP), fazendo com que acabam se tornando mais complexos que as arquiteturas MPP. Apesar disso, os clusters HPC mantém o mesmo nível de transparência do ponto de vista do usuário, em relação a estas arquiteturas MPP. Isso ocorre graças a aplicação do conceito de imagem única do sistema (SSI), visto anteriormente.
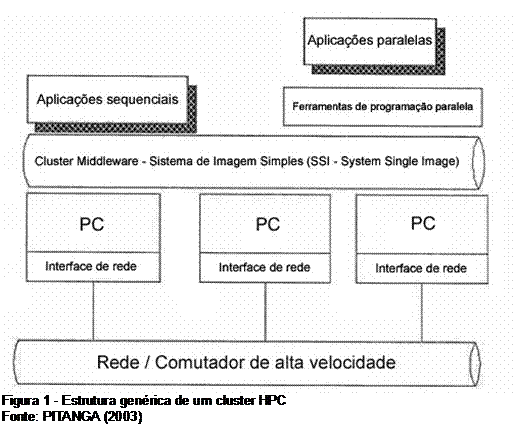
Na figura 6 é ilustrado uma estrutura básica de um cluster HPC, composto basicamente de computadores comuns interligados por uma rede de alta velocidade. Na camada "cluster middleware", conforme visto no capítulo anterior, todos os serviços responsáveis pela criação de um sistema de imagem única são implementados nela, fazendo com que o usuário final tenha uma visão simplificada do cluster, como se fosse um único supercomputador. O interessante é que esta camada pode ser implementada em apenas um dos nós do agrupamento, geralmente feita no nó controlador. Além disso, o nó controlador atua como o responsável por escalonar as tarefas entre os demais nós (escravos), além do monitoramento das atividades do sistema como um todo.
Acima da camada onde o SSI é implementado, existem ainda duas camadas num mesmo nível: a das aplicações sequencias e a das aplicações paralelas. A primeira camada permite a execução de aplicações sequencias comuns, apesar de pouco aproveitarem dos recursos que o cluster tem a oferecer. Já na outra camada, as aplicações paralelas são executadas, de forma a aproveitar todo o potencial do agregado.
É importante ressaltar que Imediatamente abaixo a camada de aplicações paralelas, e logo acima da camada de middleware, existe uma sub-camada intitulada de "ferramentas de programação paralela". Essas ferramentas são responsáveis por fornecer um ambiente de programação específica para os clusters de alto desempenho. Essas ferramentas e o ambiente de programação paralela consequentemente criado, são compostas de bibliotecas de programação paralela e linguagem de programação especificamente ajustadas para serem capazes de interagir com a camada de middleware, de forma a possibilitar a exploração de todo poder de processamento fornecido pelo cluster HPC.
Com a popularização dos clusters de alto desempenho, os ambientes de programação paralela foram uma das áreas da computação que mais evoluíram, surgindo diversas arquiteturas e bibliotecas de programação, sendo duas mais amplamente utilizadas: a PVM (Paralell Virtual Machine) e a MPI (Message Passing Interface). Ambas serão tratadas mais adiante neste capítulo.
Com o amadurecimento no desenvolvimento dos clusters de alto desempenho e sua adaptação para uso nos mais diversos ambientes computacionais, várias implementações surgiram, cada uma com características específicas e voltadas para a resolução de um determinado tipo de problema. Dentre as implementações, algumas se destacaram, como por exemplo o cluster Beowulf e o OpenMosix. Essas e outras implementações serão abordadas na seção 4.2.
ÁREAS DE APLICAÇAO
Como visto anteriormente, os clusters de alto desempenho são amplamente utilizados em diversas áreas da ciência, em empresas e outros tipos de organizações. Devido ao seu baixo custo, implementação relativamente fácil e o grande poder de flexibilidade e escalabilidade, esses clusters vem sendo uma solução eficaz.
De acordo com HPCCommunity (2010), os clusters HPC são utilizados nas mais diversas áreas da ciência moderna, rodando aplicações que exigem desde um pequeno número de nós a até aplicações que exigem um processamento massivo, com o uso de milhares de nós. Dentre algumas áreas científicas onde os clusters são amplamente utilizados, destacam-se as seguintes:
Bio informática – Nesse ramo da ciência, onde a biologia e a informática andam juntas, um dos exemplos de software é o mpiBLAST, que é uma implementação paralela do NCBIBlast. Esse programa foi utilizado para a realização de busca e comparação de cadeias genéticas;
Dinâmica molecular – Nesta área, os clusters HPC são utilizados para realizar simulações de dinâmicas moleculares e também minimização do uso de energia. Um exemplo de programa utilizado para ser executado no agregado é o GROMACS. O famoso projeto GENOMA também faz uso dos clusters de alto desempenho;
Química quântica – Através do sistema MPQC, que é um programa de química quântica massivamente paralela. Através dele, são computados as propriedades dos átomos e moléculas dos princípios ativos usando uma equação matemática específica que acaba gerando uma grande carga computacional.
Não é só na área das ciências especializadas que os clusters de alto desempenho são utilizados. Segundo Alves (2002), existem diversas outras áreas onde os clusters de alto desempenho, tais como:
Segurança da informação – Os clusters HPC são utilizados para testarem sistemas de criptografia através de simulações de ataques de força bruta e outros tipos de ataques, com intuito de descobrir as fragilidades dos sistemas criptográficos e as respectivas soluções;
Bancos de dados – Através do processamento paralelo, o tempo de pesquisas intensivas podem ser drasticamente reduzidas;
Computação gráfica – O tempo de renderização de imagens e vídeos criados por computação gráfica exigem uma grande demanda de processamento. Um filme de longa metragem poderia demorar meses para ser completamente renderizado em um computador comum. Através dos clusters, este tempo pode ser reduzido para algumas horas. Filmes que usam muitos efeitos especiais gerados por computação gráfica, como por exemplo o Titanic e Matrix, utilizaram de clusters heterogêneos para renderizar as cenas;
Previsão do tempo – Com o uso de computação paralela realizada através dos clusters, o processo de previsão do tempo é acelerado e a precisão é aumentada;
Pesquisas militares – Os clusters são utilizados em simulações dos efeitos do uso de armas nucleares, no processamento dos dados de radares usados em mísseis antibalísticos, geração de mapas, etc.
Como visto, os clusters de alto desempenho são amplamente usados nas mais diversas áreas, provando suas potencialidades e deixando nítida a percepção que, de fato, é a melhor opção de custo versus benefício entre todas as opções de arquiteturas computacionais com alta performance computacional.
PRINCIPAIS CLUSTERS DE ALTO DESEMPENHO
Cluster Beowulf
Segundo Bookman (2003), o cluster Beowulf virou sinônimo de computação paralela, sendo o agregado computacional mais amplamente conhecido e implementado. Desenvolvido pela NASA, o Beowulf foi projetado com a ideia de se utilizar computadores com hardware comuns e softwares livres. O projeto inicial era composto de 16 computadores com processador 486 DX4 interligados por uma rede padrão Ethernet.
De acordo com Pitanga (2003), o projeto surgiu a partir da necessidade de um grupo de cientistas, que necessitavam de um supercomputador com capacidade de processamento suficiente para realizar diversos cálculos exigidos por alguns projetos em andamento. Como o preço de um computador desse porte era extremamente alto e não era possível sua compra, o grupo começou a estudar uma saída para sair deste problema. A partir disso surgiu o projeto Beowulf, onde conseguiram atingir seus objetivos gastando apenas 10% do valor de um supercomputador com capacidade de processamento equivalente.
| Página anterior | Voltar ao início do trabalho | Página seguinte |
|
|
|




