Página anterior Página anterior | Voltar ao início do trabalho | Página seguinte  |
Um problema com relação à validade dos testes surge quando se têm estruturas da matriz de covariâncias diferentes das estruturas de simetria composta, erros independentes e a condição de H-F, levando a testes F não exatos.
Para verificar se a matriz de covariâncias atende à condição de H-F, Mauchly (1940) propôs um teste chamado teste de esfericidade, que verifica se uma população multivariada apresenta variâncias iguais e correlações nulas.
Meredith & Stehman (1991) verificaram que a violação da condição de H-F leva a testes liberais para os fatores da subparcela.
Caso a condição de H-F para a matriz S de covariâncias não seja satisfeita, uma alternativa seria a análise multivariada, também conhecida como análise de perfis, que adota uma hipótese mais geral sobre a estrutura da matriz de covariâncias. Outra possibilidade seria utilizar análise univariada no esquema de delineamento de parcelas subdivididas para análise de dados de medidas repetidas, realizando o ajuste do número de graus de liberdade do teste F para o fator da subparcela.
Uma desvantagem da análise multivariada, segundo Meredith & Stehman (1991), é a falta de poder para estimar os parâmetros da matriz de covariâncias, isto quando t (número de ocasiões medidas ou tempos) é grande e n (tamanho da amostra) é pequeno.
Sob a condição de H-F, os testes univariados para o efeito intra-indivíduos são usualmente mais poderosos que os testes multivariados, proporcionando uma maior probabilidade de detectar efeitos significativos, quando esses realmente existem, Meredith & Stehman (1991).
As correções para os números de graus de liberdade foram inicialmente propostas por Box (1954 a, b), e aperfeiçoadas por Geisser & Greenhouse (1958) e Huynh & Feldt (1976). Essas correções são efetuadas pela multiplicação de um valor pelo número de graus de liberdade do fator da subparcela. Para a obtenção dessas correções considera-se sij a i-ésima linha e a j-ésima coluna da matriz de covariâncias amostral S(txt), como sendo o erro experimental intra-indivíduos. Escolhem-se q = (t-1) contrastes ortogonais normalizados, sobre t medidas repetidas e toma-se a matriz C(qxt) onde as linhas são contrastes ortogonais normalizados nas t medidas repetidas. Calculando-se a matriz A(qxq) = CSC', com aij definindo um elemento genérico, pode-se obter então o
ajuste de GEISSER-GREENHOUSE 
e o ajuste de HUYNH-FELDT ![]()
onde N é o número total de indivíduos, b é o número de blocos, e t é o número de medidas repetidas (tempos).
De acordo com Muller & Barton (1989), com a correção do número de graus de liberdade obtêm-se testes mais conservativos, que são limitados a assegurar que a esteja abaixo de um certo nível. Isso para casos em que um teste aproximado não é desejável, e para casos onde a matriz de covariâncias é diferente de tratamento para tratamento.
Outra opção de análise quando a condição de H-F não é satisfeita, é o ajuste de modelos mistos que podem envolver curvas de crescimento ou modelos polinomiais, que incluam a matriz de covariâncias que melhor explique o comportamento dos dados. Esses modelos levam em conta vários tipos de estruturas da matriz de covariâncias, sendo que o melhor modelo poderia ser escolhido por um teste de razão de verossimilhança ou pelo critério de informação de Akaike que penaliza os modelos com um número grande de parâmetros.
O enfoque multivariado e o ajuste de modelos mistos não serão discutidos neste trabalho, onde será dado ênfase ao modelo univariado para análise de medidas repetidas, que é o caso mais utilizado na prática.
Considerando-se um experimento aleatorizado em blocos seguindo o esquema de parcelas subdivididas no tempo (análise de medidas repetidas), tem-se o seguinte modelo matemático sugerido por Vonesh & Chinchilli (1997):
![]() (1)
(1)
onde:
yijk é o valor observado para a variável resposta no k-ésimo tempo para o j-ésimo tratamento no i-ésimo bloco. m é uma constante inerente a todas as observações. bi é o efeito do i-ésimo bloco. tj é o efeito do j-ésimo tratamento. (bt)i é o efeito aleatório devido a interação do i-ésimo bloco com o j-ésimo tratamento. gk é o efeito do k-ésimo tempo observado. (tg)jk é o efeito da interação entre o j-ésimo tratamento com o k-ésimo tempo, e eijk é o erro aleatório correspondente à observação do k-ésimo tempo para o j-ésimo tratamento no i-ésimo bloco (variação do acaso sobre as observações), supostos homocedásticos, independentes e normalmente distribuídos.
onde:
i = 1, ..., b é o índice para níveis do fator blocos; j = 1, ..., g é o índice para níveis do fator entre indivíduos (tratamentos), e k= 1, ..., t é o índice para níveis do fator intra-indivíduos (tempos).
O objetivo deste trabalho é simular algumas situações em que as suposições para o modelo (1) são válidas, ou não, para verificar a acurácia dos testes F que envolvem a subparcela.
Segundo Dias (1996), para se gerarem variáveis aleatórias multivariadas é necessário levar em conta a estrutura de correlação multivariada, que faz com que várias variáveis sejam geradas coletivamente, tornando o processo de simulação mais complexo do que para o caso univariado. Uma distribuição t-dimensional pode ser representada como um produto de t distribuições condicionais.
A geração de variáveis aleatórias de uma distribuição multivariada pode ser realizada pela geração, em seqüência, de observações de cada uma das distribuições condicionais, através da densidade conjunta do vetor aleatório X, que pode ser fatorado da seguinte forma:
f(x1, x2,...,xt) = f1(x1) f2 (x2 / x1)... ft(xt / x1,..., xt-1)
Segundo Boswell (1993), os principais obstáculos para a implementação desse método são: determinação da distribuição condicional, e identificação de uma técnica de geração univariada adequada para cada uma das distribuições condicionais.
MATERIAL E MÉTODOS
O método utilizado para a geração dos dados foi o das distribuições condicionais. Já que o mesmo reduz o problema da geração de um vetor t-dimensional em uma série de t gerações univariadas (Johnson, 1987).
Foram simulados dados através do "software" SAS, utilizando-se as distribuições multinormal e normal contaminada (que é a soma de duas normais ponderadas).
Para a geração de variáveis aleatórias normais multivariadas, o método das distribuições condicionais supõem que X segue uma distribuição normal multivariada com vetor de médias m = (m1,..., mt) e matriz de covariâncias S = (sij) positiva definida. Para i = 1, ..., t, define-se X(i)=(X1,..., Xi)' como vetor da primeira componente de X. Assim, de X simulado através da distribuição normal tem-se que XÇNt(m, S), e dados simulados através da distribuição normal contaminada
XÇ[aNt(m1, S1)+(1-a)Nt(m2, S2)]
onde a e (1-a) são as ponderações utilizadas.
Para os casos simulados com a normal contaminada as ponderações utilizadas foram a = 0,05; 0,10; 0,15 e 0,20.
Para a simulação foi considerado o modelo matricial:
Y(gbxt)=X(gbx(g+b+1)B ((g+b+1)xt)+Y(gbxt)
onde g é o número de tratamentos, b é o número de blocos , t é o número de medidas repetidas, Y é a matriz dos dados observados gbxt de t respostas para os n = gb indivíduos, X é a matriz gbx(g+b+1) de delineamento conhecida. Essa matriz corresponde aos valores da variável explanatória e das variáveis "dummy" associadas com a classificação das variáveis, B é a matriz (g+b+1)xt de parâmetros dos efeitos fixos desconhecidos, e Y é a matriz gbxt do erro experimental.
Malheiros (1999) simulou dados em um esquema de aleatorização em blocos, com um delineamento no esquema parcelas subdivididas para análise de dados com medidas repetidas no tempo, provenientes de uma distribuição multinormal, considerando, porém, com variâncias iguais para as estruturas de covariâncias utilizadas e valores pequenos para os efeitos do fator. Neste trabalho serão simulados dados com a distribuição multinormal e a distribuição normal contaminada, levando-se em conta estruturas de matrizes de covariâncias com maior variabilidade do que aquelas utilizadas pelo autor.
Além disso considerar-se-ão duas situações para os efeitos dos fatores, ou seja, efeitos nulos e efeitos não nulos, da mesma forma como em Malheiros (1999).
Através dos resultados obtidos com simulações utilizando efeitos nulos, verificar-se-á se os níveis mínimos de significância dos testes F, associados às hipóteses para a subparcela e interação parcelaxsubparcela, apresentam distribuição uniforme (0,1).
De acordo com Malheiros (1999), esses níveis mínimos de significância são distribuídos em classes de frequências de amplitude 0,05, no intervalo (0,1), tendo-se dessa forma 20 classes de frequências. A acurácia dos testes F na análise univariada será avaliada através de um teste Qui-quadrado para testar a hipótese de aderência da distribuição dos níveis mínimos de significância à distribuição uniforme. A acurácia dos testes F será melhor quanto mais os níveis mínimos de significância se aproximam da distribuição uniforme (0,1), pois, segundo Mood et al. (1974) caso as exigências do teste F, para a análise univariada, sejam satisfeitas sob hipótese nula, os níveis mínimos de significância terão distribuição uniforme.
Com os resultados obtidos das simulações utilizando efeitos não nulos, a distribuição dos níveis mínimos de significância poderá auxiliar na detecção de situações em que os testes são mais sensíveis em indicar a existência desses efeitos (Malheiros, 1999).
Com relação aos efeitos dos fatores os dois casos observados foram:
Efeitos nulos:
b1 = b2 = b3 = b4 = 0;
a1 = a2 = a3 = a4 = a5 = 0;
t1 = t2 = t3 = t4 = t5 = t6 = 0;
at11 = at12 = at13 = at14 = at15 = at16 = at21 = at22 = at23 = at24 = at25 = at26 = at31 = at32 = at33 = at34 = at35 = at36 = at41 = at42 = at43 = at44 = at45 = at46 = at51 = at52 = at53 = at54 = at55 = at56 = 0.
Efeitos não nulos:
t1=0,108, t2=0,538, t3=-0,438, t4=0;
a1=1,045, a2=-0,856, a3=-0,065, a4=-0,480, a5=0;
t1=-9,945, t2=-7,288, t3=-4,320, t4=-2,988, t5=-0,748, t6=0;
at11=-0,74, at12=-0,963, at13=-1,428, at14=-0,125, at15=-0,188, at16=0, at21=1,105, at22=-0,583,at23=-0,803, at24=-0,01, at25=-0,203, at26=0, at31=0,645, at32=-0,545, at33=-0,70, at34=0,363, at35=-0,2, at36=0, at41=0,668, at42=-0,273, at43=-0,898, at44=0,148, at45=-0,218, at46=0, at51=0, at52=0, at53=0, at54=0, at55=0 e at56=0.
O desbalanceamento dos dados também foi estudado, pois foram simulados experimentos balanceados e desbalanceados com uma casela vazia, onde as observações para i = 2, k = 2 e j = 1, 2, 3 e 4 foram eliminadas.
Os experimentos simulados no SAS levaram em conta o delineamento de blocos ao acaso no esquema de parcelas subdivididas no tempo, com 4 blocos, 5 tratamentos e 6 tempos.
No total foram considerados 32 casos para as simulações, levando em conta as combinações entre a distribuição normal com 8 estruturas de matriz de covariâncias, efeitos nulos e não nulos, dados balanceados e desbalanceados. Procedimento semelhante foi adotado para a distribuição normal contaminada, resultando em 128 casos considerados para as simulações, com suas respectivas ponderações. Para cada caso 1.000 experimentos foram simulados.
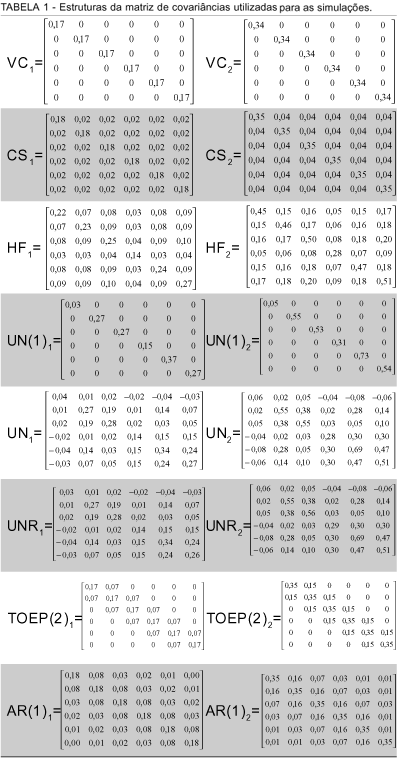
São apresentadas na TABELA 1, as estruturas das matrizes de covariâncias utilizadas para as simulações com a distribuição multinormal e a distribuição normal contaminada. Foram consideradas as matrizes de covariâncias mais citadas e utilizadas em artigos para análise de dados de medidas repetidas. Na primeira coluna da TABELA 1 encontram-se as matrizes utilizadas para a simulação de dados da distribuição normal. Com relação à simulação de dados da distribuição normal contaminada as duas colunas foram utilizadas, sendo que para as matrizes da primeira coluna foram usadas as seguintes ponderações 0,05, 0,10, 0,15 e 0,20 e para as matrizes da segunda coluna as ponderações 0,95, 0,90, 0,85 e 0,80, respectivamente.
As estruturas utilizadas foram: VC - Componentes de variâncias; CS - Simetria composta; HF - Huynh-Feldt; UN(1) - Diagonal principal "banded"; UN - Desestruturada; UNR - Desestruturada com correlações; TOEP(2) - Toeplitz "banded" e AR(1) - Auto regressiva de primeira ordem.
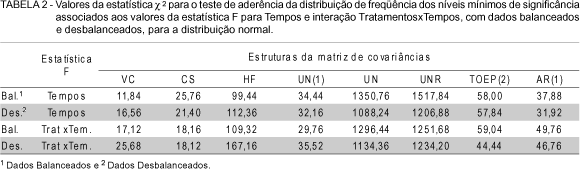
Para os casos com efeitos nulos, são apresentados nas TABELAS 2 e 3 os resultados da estatística c2 para o teste de aderência da distribuição de freqüência dos níveis mínimos de significância, dos valores da estatística F para os fatores Tempos (subparcela) e da interação TratamentosxTempos (parcelaxsubparcela), à distribuição uniforme (0,1). Os resultados apresentados na TABELA 2 são referentes aos simulados com a distribuição normal, e os da TABELA 3 com a distribuição normal contaminada.
Os valores da estatística c2 das TABELAS 2 e 3 são comparados com o valor c2 (19;0,05) = 30,14.
Dessa forma, observando-se os resultados da TABELA 2, conclui-se que para os casos simulados a partir da distribuição normal, somente para as estruturas da matriz de covariâncias VC e CS a hipótese de aderência dos níveis mínimos de significância à distribuição uniforme não foram rejeitadas, tanto para os casos de dados balanceados como para os desbalanceados.
Um detalhe importante são os resultados obtidos para a estrutura HF, da condição de H-F, pois os dados gerados a partir dessa matriz de covariâncias não produziram resultados satisfatórios quanto à acurácia da análise de variância. Esse fato chama a atenção, pois essa estrutura da matriz de covariâncias é uma condição necessária e suficiente para que os resultados do teste F para os fatores da subparcela (intra-indivíduos) sejam válidos.
Casos simulados a partir da distribuição normal contaminada, encontrados na TABELA 3, mostram que para as matrizes VC e CS, com as ponderações a = 0,05, 0,10, 0,15 e 0,20, a hipótese de aderência dos níveis mínimos de significância à distribuição uniforme não foi rejeitada, tanto para os casos de dados balanceados como desbalanceados.
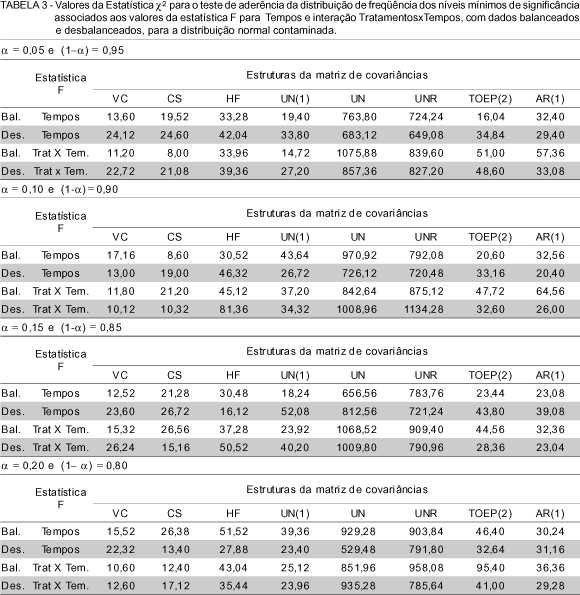
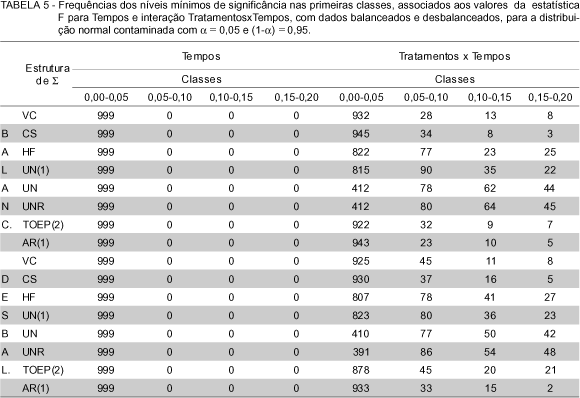
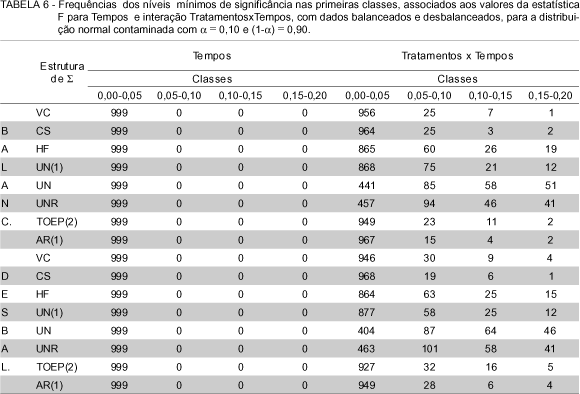
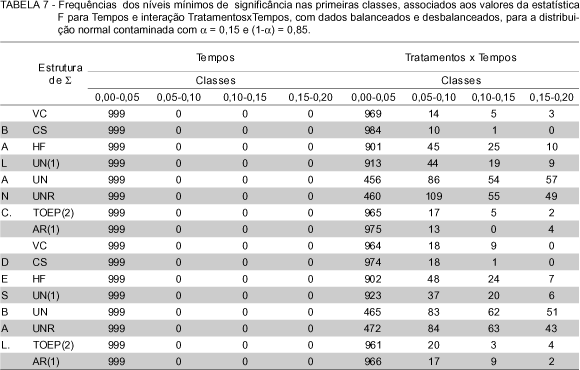
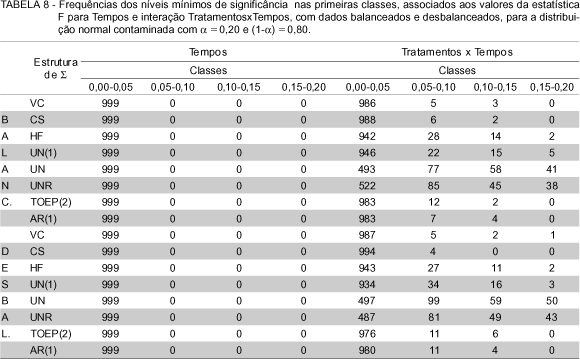
Para os casos considerados com efeitos não nulos, as frequências observadas dos níveis mínimos de significância foram dispostos nas classes de frequências (0,00 ¾ 0,05], (0,05 ¾ 0,10], (0,10 ¾ 0,15] e (0,15 ¾ 0,20]. São apresentados nas TABELAS 4, 5, 6, 7 e 8. Foram consideradas essas classes de frequências por se tomarem decisões sobre testes de hipóteses baseando-se em um nível de significância menor do que 0,20.
Através das TABELAS 4, 5, 6, 7 e 8 observa-se que independentemente do tipo da distribuição, se normal ou normal contaminada, bem como do balanceamento ou desbalanceamento dos dados, com os efeitos utilizados, em todos os casos das estruturas da matriz de covariâncias o teste superestima a indicação de efeitos, quando estes existem. Isso tanto para os testes do fator Tempos, como para a interação TratamentosxTempos.
Para os níveis mínimos de significância do fator Tempos, em nenhum dos casos as frequências (0,05-0,10], (0,10-0,15] e (0,15-0,20] apresentaram uma observação sequer. Isso se deve ao fato de que os efeitos utilizados apresentam muita diferença. Pode-se verificar isso observando os efeitos não nulos para o fator Tempos que são t1=-9,945, t2=-7,288, t3=-4,320, t4=-2,988, t5=-0,748, t6=0, por exemplo, tem-se - 9,945 para o primeiro tempo e zero para o tempo 6.
De acordo com Malheiros (1999), que trabalhou com diferentes estruturas de covariâncias, considerando, porém, que todas as estruturas tinham a mesma variância diferindo somente as covariâncias, e apresentando efeitos dos parâmetros pequenos, obteve resultados em que as matrizes de covariâncias desestruturada com correlações linearmente crescentes e decrescentes apresentaram acurácia satisfatória para a análise univariada. Também encontrou estruturas em que o teste não superestima a indicação dos efeitos quando eles existem.
Pode-se, então, concluir que dependendo dos efeitos dos parâmetros que o experimento apresenta, estes influenciam o resultado dos testes no sentido de superestimar a indicação dos efeitos, quando esses efeitos têm o intervalo de variação grande, e também quando as estruturas da matriz de covariâncias utilizadas não apresentam variâncias iguais.
Para esse caso em que as estruturas das matrizes de covariâncias para as simulações não apresentaram variâncias iguais e o intervalo de variação dos efeitos é grande, conclui-se que a análise de variância univariada só apresenta resultados válidos para as estatísticas F dos fatores intra-indivíduos se a matriz de covariâncias atender a condição de esfericidade. Caso a matriz não atenda a essa condição, correções deverão ser utilizadas para os números de graus de liberdade dos fatores intra-indivíduos, ou então, optar por modelos multivariados ou modelos mistos.
Os resultados das simulações utilizando a distribuição normal e a normal contaminada, apresentaram resultados semelhantes, ou seja, confirmaram através dos testes de aderência que a utilização de matrizes de covariâncias, que não atendam à condição de esfericidade, levam a resultados inválidos para os testes dos fatores intra-indivíduos. Somente as estruturas VC (componente de variância) e CS (simetria composta) apresentaram acurácia satisfatória para a análise de variância. Com relação à estrutura H-F (Huynh-Feldt) mais estudos devem ser realizados para se verificar o fato de que dados simulados a partir dessa estrutura, que é uma condição necessária e suficiente, não apresentem resultados razoáveis quanto à acurácia das análises.
Lara Hoffmann Xavier1,3; Carlos Tadeu dos Santos Dias2
ctsdias[arroba]carpa.ciagri.usp.br
1Depto. de Estatística - SCE - Centro Politécnico, C.P. 19081 - CEP: 81531-970 - Curitiba, PR.
2Depto. de Ciências Exatas - USP/ESALQ, C.P. 9 - CEP: 13418-900 - Piracicaba, SP.
3Bolsista CAPES.
| Página anterior | Voltar ao início do trabalho | Página seguinte |
|
|
|