Diseño de bases de datos
- Diseño de Bases de
Datos - Objetivos del diseño de
bases de datos - Conceptos
importantes - Conclusión
- Referencias
Hoy en día las empresas manejan
una gran cantidad de datos. Cualquier
empresa que se
precie debe tener almacenados todos estos datos en una base de datos
para poder
realizarlos mediante una aplicación profesional; sin esta
funcionalidad resultaría imposible tratar y manejar en su
totalidad los datos que leva a cabo la empresa y se
perdería un tiempo y un
dinero muy
valiosos
Uno de los pasos cruciales en la construcción de una aplicación que
maneje una base de datos, es sin duda, el diseño
de la base de datos.
Si las tablas no son definidas apropiadamente, podemos
tener muchos dolores de cabeza al momento de ejecutar consultas a
la base de datos para tratar de obtener algún tipo de
información.
No importa si nuestra base de datos tiene sólo 20
registros, o
algunos cuantos miles, es importante asegurarnos que nuestra base
de datos está correctamente diseñada para que tenga
eficiencia y
que se pueda seguir utilizando por largo del tiempo.
En este artículo, se mencionarán algunos
principios
básicos del diseño de base de datos y se
tratarán algunas reglas que se deben seguir cuando se
crean bases de
datos.
Dependiendo de los requerimientos de la base de datos,
el diseño puede ser algo complejo, pero con algunas reglas
simples que tengamos en la cabeza será mucho más
fácil crear una base de datos perfecta para nuestro
siguiente proyecto.
Son muchas las consideraciones a tomar en cuenta al
momento de hacer el diseño de la base de datos,
quizá las más fuertes sean:
- La velocidad de
acceso, - El tamaño de la
información, - El tipo de la información,
- Facilidad de acceso a la
información, - Facilidad para extraer la información
requerida, - El comportamiento del manejador de bases de datos
con cada tipo de información.
No obstante que pueden desarrollarse sistemas de
procesamiento de archivo e incluso
manejadores de bases de datos basándose en la experiencia
del equipo de desarrollo de
software logrando
resultados altamente aceptables, siempre es recomendable la
utilización de determinados estándares de
diseño que garantizan el nivel de eficiencia mas alto en
lo que se refiere a almacenamiento y
recuperación de la información.
De igual manera se obtiene modelos que
optimizan el aprovechamiento secundario y la sencillez y
flexibilidad en las consultas que pueden proporcionarse al
usuario.
OBJETIVOS DEL
DISEÑO DE BASES DE DATOS
Entre las metas más importantes
que se persiguen al diseñar un modelo de
bases de datos, se encuentran las siguientes que pueden
observarse en esta figura.
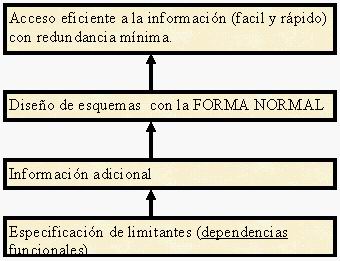
- Almacenar Solo La Información
Necesaria.
A menudo pensamos en todo lo que quisiéramos que
estuviera almacenado en una base de datos y diseñamos la
base de datos para guardar dichos datos. Debemos de ser realistas
acerca de nuestras necesidades y decidir qué
información es realmente necesaria.
Frecuentemente podemos generar algunos datos sobre la
marcha sin tener que almacenarlos en una tabla de una base de
datos. En estos casos también tiene sentido hacer esto
desde el punto de vista del desarrollo de la
aplicación.
1.2. Normalizar la Estructura de
las Tablas.
Si nunca antes hemos oído
hablar de la "normalización de datos", no debemos temer.
Mientras que la normalización puede parecer un tema
complicado, nos podemos beneficiar ampliamente al entender los
conceptos más elementales de la
normalización.
Una de las formas más fáciles de entender
esto es pensar en nuestras tablas como hojas de
cálculo. Por ejemplo, si quisiéramos seguir la
pista de nuestra colección de CD’s en
una hoja de
cálculo, podríamos diseñar algo parecido
a lo que se muestra en la
siguiente tabla.
+————+————-+————–+ ..
+————–+
| Álbum | track1 | track2 | | track10
|
+————+————-+————–+ ..
+————–+
Esto parece razonable. Sin embargo el problema es que el
número de pistas que tiene un CD varía bastante.
Esto significa que con este método
tendríamos que tener una hoja de cálculo
realmente grande para albergar todos los datos, que en los peores
casos podrían ser de hasta 20 pistas. Esto en definitiva
no es nada bueno.
Uno de los objetivos de
una estructura de tabla normalizada es minimizar el número
de "celdas vacías". El darnos cuenta de que cada lista de
CD’s tiene un conjunto fijo de campos (título,
artista, año, género) y
un conjunto variable de atributos (el número de pistas)
nos da una idea de cómo dividir los datos en
múltiples tablas que luego podamos relacionar entre
sí.
Mucha gente no esta familiarizada con el concepto
"relacional", de manera sencilla esto significa, que grupos parecidos
de información son almacenados en distintas tablas que
luego pueden ser "juntadas" (relacionadas) basándose en
los datos que tengan en común.
Es necesario que al realizar la estructura de una base
de datos, esta sea flexible. La flexibilidad está en el
hecho que podemos agregar datos al sistema
posteriormente sin tener que rescribir lo que ya tenemos. Por
ejemplo, si quisiéramos agregar la información de
los artistas de cada álbum, lo único que tenemos
que hacer es crear una tabla artista que esté relacionada
a la tabla álbum de la misma manera que la tabla pista.
Por lo tanto, no tendremos que modificar la estructura de
nuestras tablas actuales, simplemente agregar la que hace
falta.
La eficiencia se refiere al hecho de que no tenemos
duplicación de datos, y tampoco tenemos grandes cantidades
de "celdas vacías".
El objetivo
principal del diseño de bases de datos es generar tablas
que modelan los registros en los que guardaremos nuestra
información.
Es importante que esta información se almacene
sin redundancia para que se pueda tener una recuperación
rápida y eficiente de los datos.
A través de la normalización tratamos de
evitar ciertos defectos que nos conduzcan a un mal diseño
y que lleven a un procesamiento menos eficaz de los
datos.
Podríamos decir que estos son los principales
objetivos de la normalización:
- Controlar la redundancia de la
información. - Evitar pérdidas de
información. - Capacidad para representar toda la
información. - Mantener la consistencia de los datos.
- Seleccionar el Tipo de Dato
Adecuado.
Una vez identificadas todas las tablas y columnas que
necesita la base de datos, debemos determinar el tipo de dato de
cada campo. Existen tres categorías principales que pueden
aplicarse prácticamente a cualquier aplicación de
bases de datos:
- Texto
- Números
- Fecha y hora
Cada uno de éstos presenta sus propias variantes,
por lo que la elección del tipo de dato correcto no
sólo influye en el tipo de información que se puede
almacenar en cada campo, sino que afecta al rendimiento global de
la base de datos.
A continuación se dan algunos consejos que nos
ayudarán a elegir un tipo de dato adecuado para nuestras
tablas:
- Identificar si una columna debe ser de tipo texto,
numérico o de fecha. - Elegir el subtipo más apropiado para cada
columna. - Configurar la longitud máxima para las
columnas de texto y numéricas, así como otros
atributos.
1.4. Utilizar Índices
Apropiadamente
Los índices son un sistema especial que utilizan
las bases de datos para mejorar su rendimiento global. Dado que
los índices hacen que las consultas se ejecuten más
rápido, podemos estar incitados a indexar todas las
columnas de nuestras tablas.
Sin embargo, lo que tenemos que saber es que el usar
índices tiene un precio. Cada
vez que hacemos un INSERT, UPDATE, REPLACE, o DELETE sobre una
tabla, MySQL tiene
que actualizar cualquier índice en la tabla para reflejar
los cambios en los datos.
¿Así que, cómo decidimos usar
índices o no? La respuesta es "depende". De manera simple,
depende que tipo de consultas ejecutamos y que tan frecuentemente
lo hacemos, aunque realmente depende de muchas otras
cosas.
Así que antes de indexar una columna, debemos
considerar que porcentaje de entradas en la tabla son duplicadas.
Si el porcentaje es demasiado alto, seguramente no veremos alguna
mejora con el uso de un índice. Ante la duda, no tenemos
otra alternativa que probar.
1.5. Usar Consultas REPLACE
Existen ocasiones en las que deseamos insertar un
registro a
menos de que éste ya se encuentre en la tabla. Si el
registro ya existe, lo que quisiéramos hacer es una
actualización de los datos.
1.6. Usar Una Versión Reciente de
MySQL
La recomendación es simple y concreta, siempre
que esté en nuestras manos, debemos usar la versión
más reciente de MySQL que se encuentre disponible.
Además de que las nuevas versiones frecuentemente incluyen
muchas mejoras, cada vez son más estables y más
rápidas. De esta manera, a la vez que sacamos provecho de
las nuevas características incorporadas en MySQL, veremos
significativos incrementos en la eficiencia de nuestro servidor de bases
de datos.
1.8. Usar Tablas Temporales.
Cuando estamos trabajando con tablas muy grandes, suele
suceder que ocasionalmente necesitemos ejecutar algunas consultas
sobre un pequeño subconjunto de una gran cantidad de
datos. En vez de ejecutar estas consultas sobre la tabla completa
y hacer que MySQL encuentre cada vez los pocos registros que
necesitamos, puede ser mucho más rápido seleccionar
dichos registros en una tabla temporal y entonces ejecutar
nuestras consultas sobre esta tabla.
Una tabla temporal existe mientras dure la
conexión a MySQL. Cuando se interrumpe la conexión
MySQL remueve automáticamente la tabla y libera el espacio
que ésta usaba.
1.7. Recomendaciones.
El último paso del diseño de la base de
datos es adoptar determinadas convenciones de nombres. Aunque
MySQL es muy flexible en cuanto a la forma de asignar nombre a
las bases de datos, tablas y columnas, he aquí algunas
reglas que es conveniente observar:
- Utilizar caracteres alfanuméricos.
- Limitar los nombres a menos de 64 caracteres (es una
restricción de MySQL). - Utilizar el guión bajo (_) para separar
palabras. - Utilizar palabras en minúsculas (esto es
más una preferencia personal que
una regla). - Los nombres de las tablas deberían ir en
plural y los nombres de las columnas en singular (es igual una
preferencia personal). - Utilizar las letras ID en las columnas de clave
primaria y foránea. - En una tabla, colocar primero la clave primaria
seguida de las claves foráneas. - Los nombres de los campos deben ser descriptivos de
su contenido. - Los nombres de los campos deben ser unívocos
entre tablas, excepción hecha de las claves.
Los puntos anteriores corresponden muchos de ellos a
preferencias personales, más que a reglas que debamos de
cumplir, y en consecuencia muchos de ellos pueden ser pasados por
alto, sin embargo, lo más importante es que la nomenclatura
utilizada en nuestras bases de datos sea coherente y consistente
con el fin de minimizar la posibilidad de errores al momento de
crear una aplicación de bases de datos.
- Base de Datos.- Cualquier conjunto de datos
organizados para su almacenamiento en la memoria
de un ordenador o computadora,
diseñado para facilitar su mantenimiento y acceso de una forma
estándar. Los datos suelen aparecer en forma de texto,
números o gráficos. Hay cuatro modelos principales
de bases de datos: el modelo jerárquico, el modelo en
red, el modelo
relacional (el más extendido hoy en
día). - Base de Datos Relacional.- Tipo de base de
datos o sistema de administración de bases de datos, que
almacena información en tablas (filas y columnas de
datos) y realiza búsquedas utilizando los datos de
columnas especificadas de una tabla para encontrar datos
adicionales en otra tabla. - Datos Elementales.- Un dato elemental, tal
como indica su nombre, es una pieza elemental de
información. El primer paso en el diseño de una
base de datos debe ser un análisis detallado y exhaustivo de los
datos elementales requeridos. - Campos y Subcampos.- Los datos elementales
pueden ser almacenados en campos o en subcampos. Un campo es
identificado por un rótulo numérico que se define
en la FDT de la base de datos. A diferencia de los campos, los
subcampos no se identifican por medio de un rótulo, sino
por un delimitador de subcampo. - Delimitador de Subcampo.- Un delimitador de
subcampo es un código de dos caracteres que precede e
identifica un subcampo de longitud variable dentro de un
campo. - DBMS: Data Base Management System (SISTEMA DE MANEJO
DE BASE DE DATOS).- Consiste de una base de datos y un
conjunto de aplicaciones (programas)
para tener acceso a ellos.à Errores
que se pueden encontrar en el diseño de una base de
datos: - Modelo de Datos.– es un conjunto de herramientas
conceptuales para describir los datos, las relaciones entre
ellos, su semántica y sus limitantes. - Redundancia.- Esta se presenta cuando se
repiten innecesariamente datos en los archivos que
conforman la base de datos. - Inconsistencia.- Ocurre cuando existe
información contradictoria o incongruente en la base de
datos. - Dificultad en el Acceso a los Datos.- Debido a
que los sistemas de procesamiento de archivos generalmente se
conforman en distintos tiempos o épocas y ocasionalmente
por distintos programadores, el formato de la
información no es uniforme y se requiere de establecer
métodos
de enlace y conversión para combinar datos contenidos en
distintos archivos. - Aislamiento de los Datos.- Se refiere a la
dificultad de extender las aplicaciones que permitan controlar
a la base de datos, como pueden ser, nuevos reportes,
utilerías y demás debido a la diferencia de
formatos en los archivos almacenados. - Anomalías en el Acceso Concurrente.-
Ocurre cuando el sistema es multiusuario y no se establecen los
controles adecuados para sincronizar los procesos que
afectan a la base de datos. Comúnmente se refiere a la
poca o nula efectividad de los procedimientos
de bloqueo. - Problemas de Seguridad.- Se presentan cuando no es
posible establecer claves de acceso y resguardo en forma
uniforme para todo el sistema, facilitando así el
acceso a intrusos.à Niveles de
Diseño: - Problemas de Integridad.- Ocurre cuando no
existe a través de todo el sistema procedimientos
uniformes de validación para los datos. - Nivel Físico.- Es aquel en el que se
determinan las características de almacenamiento en el
medio secundario. Los diseñadores de este nivel poseen
un amplio dominio de
cuestiones técnicas
y de manejo de hardware. - Nivel Conceptual.- Es aquel en el que se definen
las estructuras lógicas de
almacenamiento y las relaciones que se darán entre
ellas. Ejemplos comunes de este nivel son el diseño de
los registros y las ligas que permitirán la
conexión entre registros de un mismo archivo, de
archivos distintos incluso, de ligas hacia archivos.à
Clasificación de Modelos de Datos: - Nivel de Edición.- Es aquel en el que se
presenta al usuario final y que puede tener combinaciones o
relaciones entre los datos que conforman a la base de datos
global. Puede definirse como la forma en el que el usuario
aprecia la información y sus relaciones. - Modelos Lógicos Basados en Objetos.-
Son aquellos que nos permiten una definición clara y
concisa de los esquemas conceptuales y de visión. Su
característica principal es que permiten definir en
forma detallada las limitantes de los datos. - Modelos Lógicos Basados en Registros.-
Operan sobre niveles conceptual y de visión. Sus
características principales son que permiten una
descripción más amplia de la
implantación, pero no son capaces de especificar con
claridad las limitantes de los datos. - Modelos Físicos de Datos.- Describen
los datos en el nivel más bajo y permiten identificar
algunos detalles de implantación para el manejo del
hardware de almacenamiento.
La finalidad de este trabajo, es
dar una inducción en el tema de Diseño de
Bases de Datos, a personas ajenas al tema. De manera que por ello
los temas se presentan de una manera sencilla y sin tanta
terminología.
Nos muestra la gran importancia que para cualquier
entidad, ya sea una empresa
grande o chica, para el gobierno, hasta
para la vida cotidiana de una persona (como se
muestra en el ejemplo de los CD’s), tienen las bases de
datos. Todo gira alrededor de ellas, todos los procesos del mundo
están registrados en ellas, de ahí la importancia
de llevar a cabo un diseño eficiente y libre de errores de
las mismas.
Siempre que una persona escucha hablar de bases de datos
y de toda la terminología que las acompaña piensa
que es un tema excesivamente complicado, y no es así, todo
tiene un porque y lógica,
es cosa de familiarizarse un poco con ellas (bases de
datos).
Cuando se ven en realidad todas las ventajas que tienen,
es mas sencillo el proceso de
aprendizaje,
ya que siente que el aprender a manejarlas se vera
recompensado.
Además de los sencillas que son, es muy
fácil acceder a información, manuales y cursos
relacionados a ellas, todo esta a la mano, con la facilidad de
poner este tema en un buscador de la red y aparecerán
infinidad de temas, unos mas complejos que otros, pero siempre
uno que se adecue a las capacidades de aprendizaje de cada
persona.
Otro punto muy importante es que la mayoría son
gratis.
INTERNET.
1.-
wwww3.uji.es/~mmarques/f47/apun/node68.html.
2.-
ww.programacion.com/bbdd/articulo/bbdd_disenyo/
3.- .http://www.cindoc.csic.es/isis/03-1.htm
4.-
http://faea.uncoma.edu.ar/materias/tdbd/
5.- http://www.itlp.edu.mx/publica/tutoriales/basedat2/
LIBROS:
1.- Introducción a las
Bases de Datos: THOMSON PARANINFO, S.A. 2005
2.- Access: Los
Mejores Trucos (Anaya Multimedia):
Bluttman, Ken.
Guillermo de Jesús Saldivar
Vargas
ESCUELA: ITSON (Instituto Tecnológico de
Sonora)
FECHA: 29/NOVIEMBRE/2005