Propuesta de guía para el estudio de la estadística en las carreras de ciencias sociales (página 2)
Muestra: Conjunto de observaciones que se toma de alguna fuente
de observación con el objetivo de obtener información respecto
a ella.
Población: Fuente de información de donde se toman las
muestras.
Los métodos estadísticos sirven para obtener conclusiones acerca de la población por medio de muestras.
Los datos que se toman dentro de una población pueden ser:
Cualitativos: Color, forma, categoría, etc y Cuantitativos: Altura, peso, cantidad,
A su vez todos los datos cuantitativos pueden ser variables discretas o continuas.
Variables discretas: Son aquellas que sólo pueden alcanzar un número finito o infinito numerable de valores, surgen generalmente de conteos por tanto sólo pueden tomar valores de números enteros. Ej. Número de cines, cantidad de aficionados, etc.
Variables continuas: Son aquellas que pueden alcanzar infinitos valores no numerables dentro de un rango determinado, están asociadas a variables de longitud, peso, tiempo por tanto pueden tomar valores de números reales. Ej. Longitud de una pieza, peso de un niño al nacer, etc.
Cuando se realiza un estudio en una población se pueden obtener datos que se repitan mas que otros, a este fenómeno lo llamaremos frecuencia de observaciones. Estas frecuencias se pueden agrupar en diversas categorías o intervalos a los que llamaremos intervalos de clase cuando el conjunto de observaciones es muy grande, realizándose lo que se llama una distribución de frecuencias, lo cual permite realizar un mejor análisis del comportamiento de los datos dentro de un conjunto pudiéndose llegar a conclusiones mas acertadas acerca de su distribución.
Las frecuencias pueden ser absolutas o relativas y simples o acumuladas
Llamamos frecuencia absoluta simple (ni) al número de observaciones en cada clase o intervalo de clase y frecuencia absoluta acumulada (Nr) a la frecuencia absoluta que se va acumulando hasta el último intervalo (r).
Llamamos frecuencia relativa simple (fi) al por ciento de observaciones que pertenecen a cada clase y frecuencia relativa acumulada (Fr) a la frecuencia relativa que se va acumulando hasta el último intervalo (r).
Observen que:
 donde n es el número
donde n es el número
total de observaciones
 donde Nr es la frecuencia
donde Nr es la frecuencia
absoluta que se va acumulando hasta el intervalo r
 donde Fr es la frecuencia relativa que se acumula hasta el intervalo r
donde Fr es la frecuencia relativa que se acumula hasta el intervalo r
Trabajaremos con un ejemplo con datos simples, es decir los datos no están agrupados en intervalos de clases.
Distribución de frecuencias para variables discretas
Ejemplo 1
Para hacer una distribución de planes vacacionales se consideró el número de personas por núcleo familiar de los integrantes de una institución cultural. Las observaciones se denotan por xi donde i varía desde 1 hasta 20 ( n=20).
Los valores observados son los siguientes:
2,3,4,2,4,4,5,6,4,2,5,6,4,4,4,3,5,3,4,5 los cuales constituyen los datos primarios de la muestra observada
Estos datos se pudieran organizar en orden ascendente
2,2,2,3,3,3,4,4,4,4,4,4,4,4,5,5,5,5,6,6
O en orden descendente
6,6,5,5,5,5,4,4,4,4,4,4,4,4,3,3,3,2,2,2
O en una tabla de distribución de frecuencias
Tabla 1

Ejemplo 2
Para datos agrupados
Se está desarrollando un estudio para caracterizar un grupo de
jóvenes a los que se le ha aplicado un programa comunitario de salud
y para ello se tomó una muestra en la que se relaciona la estatura de
40 personas en cm.
Tabla 2
175 | 173 | 181 | 169 | 195 | 196 | 177 | 174 |
170 | 168 | 185 | 173 | 170 | 168 | 172 | 179 |
184 | 183 | 176 | 188 | 179 | 177 | 172 | 180 |
193 | 195 | 178 | 187 | 190 | 192 | 188 | 180 |
172 | 169 | 171 | 176 | 184 | 183 | 180 | 179 |
Antes de construir una tabla de distribución de frecuencias debemos saber primeramente cuántos intervalos de clase tendrá la misma y de qué tamaño serán esos intervalos. La cantidad dependerá de nuestros fines y posibilidades y en algunos casos de las características del método a aplicar. De todas formas como criterio práctico estos deben variar entre 5 y 20 intervalos. El tamaño del intervalo dependerá del número de intervalos que se seleccionó.
Para este ejemplo tomaremos 7 intervalos de clase (k=7)
Calculemos el rango de variación de los datos que no es mas que la diferencia entre los valores máximos y mínimos de una muestra.

Es necesario aclarar que la aproximación siempre debe ser realizada por exceso
Procederemos a construir los intervalos de clases.
Para dar este paso se debe comenzar por el menor valor de las observaciones (Xmin), el cual constituye el límite inferior de la primera clase. A este valor se le suma el tamaño del intervalo y se obtendrá entonces el límite superior de la primera clase. A partir de este valor se continúa construyendo la segunda clase siguiendo el procedimiento antes descrito.
Tabla 3
i | Intervalos de clase | ||||
1 | 168 = X = 172 | ||||
2 | 172 < X = 176 | ||||
3 | 176 < X = 180 | ||||
4 | 180 < X = 184 | ||||
5 | 184 | ||||
6 | 188 | ||||
7 | 192 | ||||
Al agrupar los datos en una tabla de distribución de frecuencias se pierde información, nos encontraremos un grupo de datos que en sus valores originales difieren y que se encuentran agrupados en un rango de valores. Se necesita por tanto un valor que represente a este conjunto de valores el cual se llamará marca de clase y que es por definición el punto medio de cada intervalo de clase.

De la tabla 2 obtenemos la siguiente información
Tabla 4
168 = X = 172 | 169,170,168,170,168,172,172,172,169,171 | ||
172 < X = 176 | 175,173,174,173,176,176 | ||
176 < X = 180 | 177,179,179,177,180,178,180,180,179 | ||
180 < X = 184 | 181,184,183,184,183 | ||
184 | 185,188,187,188 | ||
188 | 190,192 | ||
192 | 195,196,193,195 | ||
La tabla anterior nos brinda una información adicional, quedando de la siguiente forma
Tabla 5

Representaciones gráficas
Un gráfico estadístico es la representación de un fenómeno estadístico por medio de figuras geométricas (puntos, líneas, rectángulos, círculos, etc.). cuyas dimensiones son proporcionales a la magnitud de los datos presentados.
La representación de la información estadística se puede realizar de las formas siguientes:
a) Textual
b) Cuadros
c) Gráficas
Reglas para la elaboración de los gráficos
1- Debe ser lo mas simple posible, los símbolos y líneas usadas deben ser los mas estrictamente necesarios
2- Si hay dos o mas gráficos deben ser enumerados
3- Debe levar un título que aclare el contenido de la misma
4- La línea de las ordenadas(Y) representan la frecuencia y las abscisas (X) las características cualitativas y cuantitativas
5- Debe explicar la fuente donde fueron obtenidos los datos
6- Los datos numéricos sobre los que se basa el gráfico deben presentarse en cuadro adjunto
7- Deben seguir y nunca preceder al texto
8- Cuando presenta mas de una variable deberá hacerse una clara diferenciación por medio de leyendas, notas o signos convencionales que llamaremos indicadores.
Representaciones gráficas para variables continuas
Para datos continuos estudiaremos el histograma de frecuencias, el polígono y el gráfico para una distribución de frecuencias acumuladas, o sea las ojivas, ¨menor que¨ y ¨mayor que¨
Histogramas
Si la variable es continua los límites de clase se colocan en el eje horizontal y teniendo como base cada intervalo de clase levantamos un rectángulo que tenga como altura la frecuencia correspondiente a cada intervalo.
Figura 1

Para construir un polígono de frecuencias, se plotea el valor de la frecuencia de cada intervalo contra la marca de clase del intervalo correspondiente y los puntos resultantes se unen por una recta.
Figura 2

Figura 3

Gráficos para variables discretas
Gráficos de barras simples

Diagrama circular
Un gráfico circular nos muestra la partición de un conjunto en varias partes, resaltando la cantidad o porcentaje de observaciones que integran cada parte con relación al total de observaciones del conjunto.
Ejemplo: Se realizó una encuesta en una escuela secundaria a 800 estudiantes para investigar cuales eran sus preferencias culturales y se obtuvieron los siguientes resultados:
Aficionados | Cantidad | % | Grados |
Teatro | 200 | 25 | 90 |
Cine | 400 | 50 | 180 |
Ballet | 120 | 15 | 54 |
Pintura | 80 | 10 | 36 |
Total | 800 | 100 | 360 |
Para obtener el % se divide la cantidad de estudiantes por manifestación entre el total de los estudiantes (800) y después se convierten los % obtenidos en grados con la equivalencia de 1 % = 3.6 º ya que el 100 % = 360º.
Posteriormente haciendo uso del compás y el transportador se mide cada ángulo uno a continuación del otro.

Medidas de posición
Son las variables que indican la posición de un dato dentro del conjunto. Ej. La media aritmética, la moda, la mediana, etc.
La media o promedio aritmético es la suma de un conjunto de observaciones divididas entre el total de ellas. Se representa por la letra  y se calcula para datos simples o sin agrupar en intervalos de clase mediante la fórmula:
y se calcula para datos simples o sin agrupar en intervalos de clase mediante la fórmula:
 donde n = Número total de elementos que componen las muestras
donde n = Número total de elementos que componen las muestras
Cuando estimamos que la edad media de una población es de 20 años,
no se pretende hacer creer que necesariamente cada una de las personas que integran
el grupo tiene 20 años. Simplemente se está tratando de dar a
conocer una medida que sea lo más representativa de la población
a la que se hace referencia. El tipo de valores que como en el ejemplo citado
tiene por objeto presentar una situación media de una población,
se conoce como medidas de tendencia central.
Ejemplo 3
Los ingresos diarios de un establecimiento se presentan a continuación ( miles de pesos) 2.0, 2.5, 3.2, 3.1, 4.0, 1.8
Se desea conocer los ingresos promedios diarios que tuvo el establecimiento.
Aplicando la fórmula dada

Cuando las observaciones se agrupen en frecuencias la fórmula
a aplicar será:

Donde: k = Cantidad de intervalos de clase
ni = frecuencia absoluta de la clase i
xi = Marca de clase i
fi = Frecuencia relativa de la clase i
Para demostrar el uso de esta fórmula volveremos al ejemplo 2 y la tabla 5 adicionando una última columna con el objetivo de obtener el numerador de la fórmula anterior 
Tabla 6

Por tanto:

La estatura media o la estatura promedio de las personas es de 178.9 cm.
La moda es otra medida de tendencia central muy usada y no es más que el valor mas frecuente de un grupo de observaciones. Ejemplo de los números 46, 52, 48, 46, 52, 50, 47, 49, 46 el valor modal es 46 ya que se encuentra representado tres veces en el conjunto. Pueden existir masas de datos con mas de una moda al igual que puede que no exista la misma.
Cuando los datos son agrupados la moda se calcula por la siguiente fórmula:

En este caso sería:
L = 168, d1 = 10-0 = 10, d2 = 10-6 = 4, C = 172 – 168 = 4
Sustituyendo en la fórmula

Como se puede apreciar la clase modal es la número 1 ya que la frecuencia absoluta es la mayor.
La mediana se define como el valor intermedio de un conjunto de datos ordenados de forma ascendente o descendente.
Ejemplo la mediana de las observaciones 26, 37, 43, 52, 65, 77, 88, 92, 115, 118, 126 es 77, pues después de haber organizado los datos simples en orden ascendente el valor central es 77. Para mayor rapidez se utiliza la fórmula (n+1)/2 en este caso el sexto valor es el correspondiente. Cuando el número de observaciones es par, se calcula la media aritmética de las dos observaciones centrales del arreglo, así la mediana de los valores 6, 10, 10, 11, 13, 14, 14, 17 es 11+13 = 12
2
Cuando las observaciones se presentan en categorías agrupadas por frecuencias, se puede calcular de forma aproximada el valor de la mediana por la siguiente fórmula:


Como se observa en la tabla 6 hasta la clase 2 se acumula el 40 % de las observaciones y hasta la 3 el 62.5 %, por tanto esta será la clase modal pues en ella se encuentra acumulado el 50 % de las observaciones y en ella debemos basarnos para obtener las informaciones necesarias

Cuartiles, percentiles y rangos de percentiles
Al igual que la mediana divide la distribución en 4 partes iguales, los cuartiles que se denotan por Q1/4, Q2/4, Q3/4, dividen la distribución en 4 partes iguales.
El primer cuartel Q1/4, representa aquel valor de x que supera a no mas de la cuarta parte de los datos ordenados y es superado por no mas de las ¾ partes.
El segundo cuartel Q2/4 es la mediana y el tercer cuartel Q3/4, supera a no mas de las ¾ partes de los datos y es superado por no mas de la ¼ parte.
De la misma manera se definen quintiles, deciles y cantiles los cuales son valores de x que dividen a la distribución en cinco, diez y cien partes respectivamente.
Percentiles
Un percentil es un punto que divide a la distribución de frecuencias en dos partes de tal forma que a su izquierda o por debajo de el se encuentre un determinado por ciento del total de observaciones. Se denota por Pq donde q representa que por ciento de las observaciones se encuentra por debajo de él.
Por ejemplo:

Fórmula para el cálculo de los percentiles

Medidas de dispersión
Son las variables que miden el grado de dispersión que tienen las observaciones dentro de un conjunto de datos.
Las medidas de variación mas comunes son la varianza, la desviación típica, el coeficiente de variación y la amplitud de variación ( rango ), el cual ya estudiamos anteriormente.
Para calcular la varianza se utiliza la siguiente fórmula:
Para datos sin agrupar

Donde las ni representan las frecuencias absolutas de cada clase y las xi las marcas de clase.
Propiedades de la varianza
a) Siempre es un número positivo
b) La varianza de una constante es cero
c) La varianza de una constante por una variable es igual a la constante al cuadrado por la varianza de la variable
d) La varianza de la suma de una variable y una constante es igual a la varianza de la variable
La varianza tiene una limitante ya que utiliza valores al cuadrado resultando difícil su interpretación en la generalidad de los casos. Si las observaciones se refieren a volumen en m3 resulta difícil entender una evaluación de la variabilidad en (m3)2.
Por esa razón es común extraer la raíz cuadrada al valor de la varianza para obtener la desviación típica o estándar la cual se calcula a través de las siguientes fórmulas:
Para datos sin agrupar

Las medidas de variación discutidas se expresan en valores absolutos consecuentemente no hacen válida la comparación de variabilidades entre poblaciones o muestras que se dan en unidades diferentes. Si se compara la variación en el peso de un diminuto dispositivo electrónico contra la variabilidad en el peso de ciertos automóviles, por medio de la varianza o de la desviación típica se obtendrá un mayor valor para los automóviles, en virtud de que el peso de un auto es mucho mayor que el peso de un dispositivo electrónico. Sin embargo la variabilidad intrínseca de la población pudiera ser mayor en el dispositivo electrónico que en la población de automóviles. Este problema se resuelve recurriendo a una medida relativa de dispersión que considere, además de la variación absoluta, la media de la población. Esta medida es el coeficiente de variación el cual se calcula por la siguiente expresión:

Ejemplo 3
Retomamos la tabla 6 del ejemplo 2, recordando que ya habíamos obtenido la media aritmética con un valor  = 178.9 cm
= 178.9 cm

Sustituyendo los resultados en la fórmula de la varianza obtenemos:

Lo cual significa que la estatura de ese grupo poblacional tiene una variación de un 4.28 % con respecto a la estatura media.
TEMA II
Correlación y regresión lineal
Hasta el momento hemos estudiado métodos estadísticos para estimar parámetros de poblaciones normales. A partir de este momento incurriremos levemente en el campo de la estadística inferencial, utilizaremos dos herramientas claves dentro del estudio de las relaciones entre variables, una es la correlación lineal y otra es la regresión, las cuales están estrechamente vinculadas.
La correlación permite medir si la relación entre variables se puede considerar lineal o no y el análisis de regresión simple permite encontrar la ecuación matemática que describe la relación entre esas variables si es fuerte o es débil.
Correlación
Para determinar la relación existente entre dos variables aleatorias X y Y lo primero que debemos hacer es llevar a un sistema de ejes cartesianos las parejas de valores (x,y) o sea los puntos (x1,y1); (x2,y2); .; (xn,yn), resultantes de las n observaciones de dichas variables.
Ejemplo 4
Sean X = gastos de investigación y desarrollo (mp)
Y = ganancia anual (mp)
X | 2 | 3 | 4 | 5 | 7 | 4 | 6 |
Y | 4 | 7 | 10 | 11 | 16 | 5 | 14 |
Aplicando los conocimientos anteriores construimos el gráfico correspondiente

Como se puede apreciar a partir del gráfico se puede determinar si hay relación o no entre las variables y si esta relación se aproxima o no a una línea recta. Si es una recta ascendente la relación es lineal, positiva y directa, mientras que si es una recta descendente la relación es lineal, negativa e inversa.
Lo importante ahora es medir cuán fuerte es la relación y de ello se encarga el coeficiente de correlación.
El coeficiente de correlación toma valores desde -1 hasta 1. Si toma valores positivos indicará que ambas variables crecen simultáneamente y si una variable crece mientras la otra decrece, su valor será negativo. La proximidad a 1 ó a -1 indicará mayor fortaleza de la relación entre las variables y en la medida que nos aproximamos a cero esta relación es más débil.
Podemos resumir diciendo que:
Valores de r | Significado de este valor | ||
-1 | Relación lineal negativa perfecta entre las variables Y y X | ||
)-1,0( | Relación lineal negativa mas o menos fuerte entre las variables | ||
0 | Ausencia de relación lineal entre las variables | ||
)0,1( | Relación lineal positiva mas o menos fuerte entre las variables | ||
1 | Relación lineal positiva perfecta entre las variables | ||
Ahora emplearemos la fórmula para calcular el coeficiente de correlación lineal y por ende conocer si la relación entre las variables estudiadas es fuerte o débil.
Fórmula para calcular el coeficiente de correlación estimado r:

Calculemos el coeficiente de regresión para el ejemplo 4 auxiliándonos de una tabla y tomando los valores de X y Y de la tabla # 4.

Y sustituyendo los valores en la fórmula anterior:

La relación entre los gastos de investigación y la ganancia se puede considerar aproximadamente como una relación lineal, positiva y fuerte ya que al aumentar los gastos de investigación también aumenta la ganancia.
Regresión lineal simple
Por lo general a los investigadores no sólo les interesa saber si existe o no una relación lineal entre las variables. En la mayoría de los casos también quieren conocer la ecuación matemática que describe en forma aproximada esta relación. Por ejemplo resultaría de gran interés saber la ganancia que obtendría una empresa a partir del monto que le dedique al desarrollo, o el costo de producción para un volumen determinado de producto, etc.
Supongamos que después de construir el diagrama de dispersión y determinar el coeficiente de correlación se llega a la conclusión de que la relación entre las dos variables es aproximadamente lineal del tipo y= a + βx. En realidad no sería una relación exacta porque sobre la variable (y) estarían actuando otras causas aleatorias llamadas errores.
En estos casos el investigador sólo dispone de una muestra de la variable aleatoria Y correspondiente a los valores de una variable X, entonces no quedará otra alternativa que utilizar estas observaciones para estimar los parámetros a y b en la ecuación y= a + βx. Si se estiman los parámetros a y β mediante los estimadores a y b respectivamente y se sustituyen los primeros por los segundos se obtendrá la ecuación de regresión estimada  a + bx
a + bx
El problema que nos ocupa es el llamado problema de regresión lineal simple.
Lineal porque los parámetros a y b lo son, simple porque intervienen dos variables, Y la variable dependiente y X la variable independiente.
Utilizando el método de los mínimos cuadrados que es el que hace mínima la suma de los errores al cuadrado se estiman los parámetros a y b a través de las siguientes fórmulas.

Calculemos la recta de regresión para el ejemplo anterior

Representando gráficamente la ecuación de la recta en el diagrama de dispersión del ejemplo

TEMA III
Tablas de contingencia
Las tablas de contingencia se utilizan para contrastar la posible independencia de dos características de los elementos muestrales. Por ejemplo, podemos contrastar si la edad de un votante está relacionada con su opinión política, el sexo de una persona con la opinión profesional que escoge, etc. En este contraste, la hipótesis nula es la ausencia de asociación entre ambas características, y la tabla de contingencia puede utilizarse con variables discretas de cualquier tipo. De hecho uno de los aspectos de interés de estas tablas es su aplicabilidad al contraste de ausencia de asociación entre variables aleatorias de tipo cualitativo.
El planteamiento de la hipótesis es fundamental a la hora de resolver cualquier problema empleando las tablas ce contingencia:

Ejemplo 5
Supongamos que se celebra un referéndum que considera la posibilidad de introducir una legislación de carácter ecológico, que lleva asociadas importantes restricciones de acceso a la zona afectada. En una muestra de 5000 votantes, 3000 mujeres y 2000 hombres, observamos que votaron a favor de introducir la legislación 1200 de los 1800 votantes menores de 25 años, 1200 de los 2100 votantes entre 25 y 35 años y 400 de los 1100 votantes mayores de 35 años. Queremos constatar la hipótesis de que la opinión de los votantes no es independiente de la edad, para lo cual construimos la tabla.
| Menores de 25 años | Entre 25 y 35 años | Mayores de 35 años | Total |
A favor | 1200 | 1200 | 400 | 2800 |
En contra | 600 | 900 | 700 | 2200 |
Total | 1800 | 2100 | 1100 | 5000 |
Lo primero que debemos hacer es el planteamiento de la hipótesis
Si se cumple H0 la opinión de los votantes es independiente de la edad
Si se cumple H1 la opinión de los votantes depende de la edad
Nótese que se quiere constatar que la opinión de los votantes depende de la edad por eso se asocia a la hipótesis alternativa, mientras que la hipótesis nula indica que no se cumple eso.
El contraste de independencia se basa en un estadístico llamado Ji cuadrado que compara las frecuencias realmente observadas en la muestra con las que teóricamente deberían haberse observado de aceptarse la hipótesis nula.
Para determinar las frecuencias esperadas utilizamos la fórmula:

Para la primera celda el total de la fila es 2800 y el total de la columna 1800 por tanto estos números multiplicados entre sí y divididos entre el total general que es 5000 se obtiene un valor de 1008 lo cual se colocaría en la primera casilla, y así sucesivamente se hace el mismo procedimiento con las restantes 5 casillas obteniéndose una nueva tabla con las frecuencias esperadas
| Menores de 25 años | Entre 25 y 35 años | Mayores de 35 años | Total |
A favor | 1008 | 1176 | 616 | 2800 |
En contra | 792 | 924 | 484 | 2200 |
Total | 1800 | 2100 | 1100 | 5000 |
Posteriormente aplicamos la fórmula para calcular el estadístico

El valor del estadístico calculado se compara con el estadístico tabulado el cual se obtiene de la siguiente manera:
X2 (Número de filas -1)(Número de columnas -1);1-a
Donde el número de filas menos 1 multiplicado por el número de columnas menos 1 son los grados de libertad, es decir (2-1)*(3-1)= 2 y 1- a es la probabilidad, y a es el nivel de significación el cual se ofrece como dato, en este caso asumiremos que es 0.05
X2 (2; 0.05) = 5.991 valor que sale de la tabla que está en la página 367 del libro de texto Estadística. Teoría Básica y Ejercicios.
Como se observa el valor del estadístico calculado es muy superior al valor tabulado 5.991 lo que sugiere que la opinión acerca de la legislación depende de la edad.
Coeficiente de correlación por rangos de Spearman
El coeficiente de correlación lineal que se estudió en el tema III solamente se puede aplicar a datos cuantitativos. Si una de las variables o ambas son cualitativas no se puede aplicar es por ello que trataremos el estudio de otra medida de asociación que es muy utilizada en el campo de la investigación social.
La correlación por rangos consiste en examinar el grado de correspondencia que existe entre los rangos que asignamos a las características cuyo grado de asociación queremos medir los cuales pueden asignarse por orden creciente o decreciente.
Cuando las observaciones muestrales no son cualitativas, sino que con cuantificables, o se pueden ordenar de acuerdo con un determinado criterio, entonces puede definirse unos seudo coeficientes de correlación, que cuantifican el grado de asociación entre distribuciones, a partir de los rangos.
El coeficiente de correlación por rangos propuesto por Carl Spearman en 1904 es:

Donde:
d: Diferencia entre los rangos correspondientes a los valores de las dos características de un mismo elemento muestral.
n: Total de observaciones
El coeficiente toma valores entre –1 y 1 al igual que el coeficiente de correlación lineal, un valor próximo a cero indicaría que ambas variables apenas tienen relación. Valores próximos a la unidad indican que ambas variables tienen una relación estrecha. Si el valor es positivo, la relación es directa, es decir cuando aumenta Y también aumenta X y cuando Y disminuye también disminuye X. Si el coeficiente de correlación por rangos es negativo, indica que valores elevados de una variable vienen asociados con valores reducidos de la otra. Al igual que con los otros estadísticos de rango, cuando varias observaciones tienen igual rango se les asigna el promedio de los rangos que les correspondería.
Ejemplo 6
Para examinar el grado de relación que existe entre las asignaturas de Estadística y Metodología de la investigación, se tomaron las notas de 15 alumnos. Tras las calificaciones de ambas materias se obtuvo las dos columnas de rangos de cada una de ellas y la columna 6 tiene las diferencias de rangos, d1 que no es sino la diferencia de las columnas anteriores.

Obsérvese que las observaciones 4 y 14 tienen rango 2.5 en la asignatura Metodología de la Investigación y esto se debe a que tienen el mismo valor ( 86 puntos ), en estos casos se promedian los rangos que le corresponderían, por ejemplo los rangos 2 y 3 (2+3)/2 = 2.5. Lo mismo ocurre con las observaciones 5 y 12.

Este valor indica una fuerte relación entre ambas calificaciones.
Ejercicios propuestos
Tema I Estadística Descriptiva.-
Ejercicio 1.- A continuación se muestra una TDF donde aparece registrada la estatura en centímetros de 40 niños de una escuela rural de la provincia de Pinar del Río.
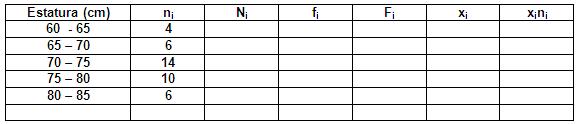
a.) Calcule la frecuencia relativa (fi) y la marca de clase (xi).
b.) ¿Cuántos niños tienen estaturas inferiores a 75 cm? ¿Qué porciento representa de la muestra?
c.) Calcule la estatura media de los estudiantes.
d.) ¿Cuál es la estatura más frecuente?
e.) ¿Por debajo de qué estatura está el 80 % de las observaciones?
f.) En la escuela rural hay una varianza de 34.9 cm2 respecto a la estatura media. Si en una escuela urbana se obtuvo una altura media de 75.5 cm con una desviación típica de 6.8 cm. ¿En cual de los casos hay una menor dispersión de la estatura de los niños.
Ejercicio 2.- Se quiere hacer un estudio del embarazo en la adolescencia en el municipio de Pinar del Río, durante el segundo semestre del año 2004 con el objetivo de tomar medidas para evitar el embarazo precoz, tomando una muestra de 100 embarazadas, comportándose de la siguiente forma:

a.) Complete la TDF y construya su histograma de frecuencia correspondiente.
b.) ¿Cuál es la edad promedio de las embarazadas?
c.) ¿Cuántas embarazadas tienen menos de 20 años? ¿Qué porciento representa del total estudiado?
d.) En el año 2003 se hizo un estudio similar al realizado en el 2004 en la misma etapa en el municipio Pinar del Río con una muestra de igual tamaño, obteniéndose un promedio de edad de 17.36 años y una desviación típica de 1.41. ¿Cuál de los dos años tiene mayor estabilidad en cuanto a la edad de las embarazadas?
e.) Calcule la moda y la mediana en la muestra analizada.
f.) ¿Qué porciento de las embarazadas se ubican en la clases que contiene a la mediana?
Ejercicio 3.- Un análisis del tiempo que los niños usan antes de acostumbrarse al uso de prótesis dentales correctivas arrojó como resultado los datos que se muestran a continuación en una muestra de tamaño 100:

a.) Complete la TDF y construya su polígono de frecuencia correspondiente.
b.) ¿Cuál es la promedio de días de adaptación de los niños a las prótesis?
c.) ¿Cuantos niños de la muestra observada se incluyen hasta la clase modal?
d.) ¿Qué porciento de los niños están incluidos en la clase que contiene a la mediana?
e.) ¿Por debajo de qué día está el 65 % de las observaciones?
Ejercicio 4.- La Tabla de Distribución de Frecuencias (TDF) correspondiente a las ventas diarias en una librería de la provincia durante 50 días observados (en pesos).

a.-) Completar la tabla.
b.-) ¿En cuántos días las ventas fueron inferiores a $ 150. pesos? ¿Qué porciento representan?
c.-) ¿Entre que valores estuvieron las mayores ventas? ¿En cuantos días se observaron?
d.-) Calcule las ventas diarias promedio de la librería.
e.-) ¿Cuál es el valor de venta más frecuente?
Tema II Análisis de Regresión.-
Ejercicio 1.- Un gerente de publicidad supone que
existe una relación directa entre los gastos de publicidad y el número
de espectadores que concurren a la sala de teatro. Los siguientes valores reflejan
el comportamiento mensual de estas dos variables:

Ejercicio 2.- La información siguiente indica el costo de producción de un artículo en pesos (x) y el precio de venta del artículo en pesos (y):

Ejercicio 3.- Se desea establecer la relación que existe entre los pagos por sobrestadía que tiene que abonar la empresa a cada camión que se descarga en sus almacenes y el tiempo que estos tienen que esperar por su descarga. Para ello se tomó una muestra aleatoria de siete camiones de los cuales se observó la cantidad de días que habían esperado y el pago que recibieron (en decenas de pesos); dando lo siguiente:

Ejercicio 4.- Para reducir los crímenes, el presidente de un país ha presupuestado más dinero para poner más policías en las calles de la ciudad.

Tema III Tablas de Contingencia.-
Ejercicio 1.- Para analizar si existe independencia entre los resultados docentes de los alumnos de primer año de la Facultad de Ciencias Humanísticas y los centros educacionales de procedencia se obtuvo la siguiente muestra.

Realice la prueba de hipótesis correspondiente. Considere un nivel
de significación del 5 %.
Ejercicio 2.- Un grupo de investigadores del MINTUR está analizando si la región de procedencia de los turistas que arriban a la provincia, dependen de la modalidad de turismo que prefieren practicar. Realice la prueba correspondiente que permita verificar la interrogante propuesta, para un nivel de significación del 5% y diga a que conclusión llegó.

Ejercicio 3.-En cierta institución se desea investigar si existe relación entre el ausentismo y los resultados laborales de los trabajadores. En base a los datos muestrales de la siguiente tabla, verifique la hipótesis anterior, mediante una prueba ?² para un nivel de significación del 1 %.

De una respuesta al problema planteado, con un nivel de significación del 1 %.
Autor:
Lic. Ariel Bravo Echevarria
Profesor Asistente
Universidad de Pinar del R?o, Cuba
 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |