
Índice
Introducción.
Entorno de trabajo.
Cloud Computing, Configuración de una Nube OpenStack.
Computación Distribuida Apache Hadoop.
Hadoop Distributed File System.
Integración Cloud Computing – Apache Hadoop.
Programación MapReduce.
Librería Hadoop Image Processing Interface.
Pruebas de Rendimiento y Ejemplo de Aplicación HIPI.
Conclusiones y Trabajo Futuro.
1

Introducción
Mejora en las comunicaciones de Red
Aumento de velocidad y del volumen de tráfico soportado
Nace Apache Hadoop
Aparición del Paradigma de Computación Cloud Computing
¿Es posible Integrarlos?
Sistema de Computación Distribuido de Alto Rendimiento en un entorno Cloud Computing
Desarrollo de los Sistemas de Computación Distribuidos
3

Cloud Computing
Ofrecer los recursos de un sistema sin que los usuarios tengan conocimientos sobre el mismo, su configuración, mantenimiento o administración.
Tipos de nubes: privadas, públicas, híbridas, combinadas y comunitarias.
5
Virtualización de Servidores.
Convertir un sistema en una infraestructura de servicios escalable, dinámica y automatizable en la que se paga por los servicios que utilizas.
Migrar servicios entre servidores y adaptar el sistema a la demanda de los usuarios.
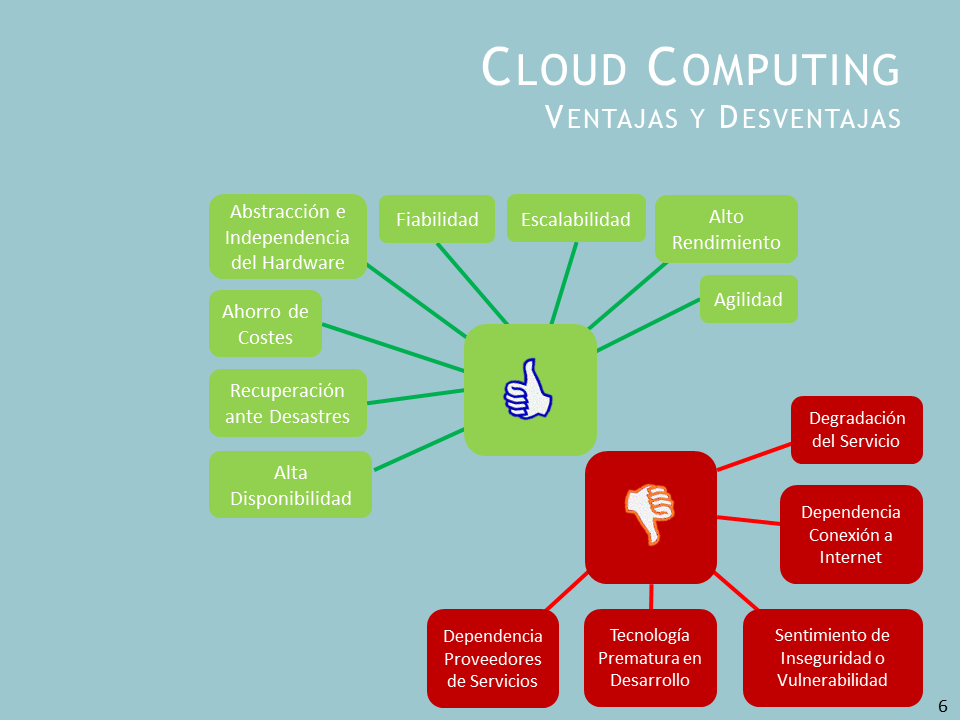
Cloud ComputingVentajas y Desventajas
Ahorro de Costes
Alta Disponibilidad
Alto Rendimiento
Fiabilidad
Escalabilidad
Agilidad
Recuperación ante Desastres
Abstracción e Independencia del Hardware
Sentimiento de Inseguridad o Vulnerabilidad
Dependencia Conexión a Internet
Tecnología Prematura en Desarrollo
Degradación del Servicio
Dependencia Proveedores de Servicios
6

Cloud ComputingComparativa

Cloud ComputingOpenStack
Red Pública
DUAL NODE
Red de Gestión
Nodo(s) de Procesamiento
Nodo Controlador
7

Cloud ComputingComputación Distribuida Apache Hadoop
Entorno de computación distribuida de licencia libre creado por Doug Cutting y promovido por Apache Software Foundation.
Aplicaciones sobre grandes volúmenes de datos de manera distribuida.
Sistemas con miles de nodos.
Alta flexiblidad y escalabilidad. Clústeres con distintas topologías.
9

Cloud ComputingComputación Distribuida Apache Hadoop
MAESTRO
ESCLAVO(S)
TASKTRACKER
JOBTRACKER
DATANODE
NAMENODE
DATANODE
TASKTRACKER
Capa
MapReduce
Capa
HDFS
10

Cloud ComputingHadoop Distributed File System
Diseño específico para Apache Hadoop
Mínimas Escrituras – Múltiples Lecturas
No posee Alta Disponibilidad
Posibilidad de Réplica de Nodos
No indicado para sistemas con múltiples archivos de poco tamaño
Posibilidad de agrupar los datos en contenedores
Tolerancia a Fallos
11

Cloud ComputingHadoop Distributed File System
NAME
NODE
NAMENODE
SECUNDARIO
DATANODE
DATANODE
Réplica de Datos
Op. Sincronización
Op. sobre
Bloque
Red de Sincronización
Op. Datos
12
Página siguiente  |