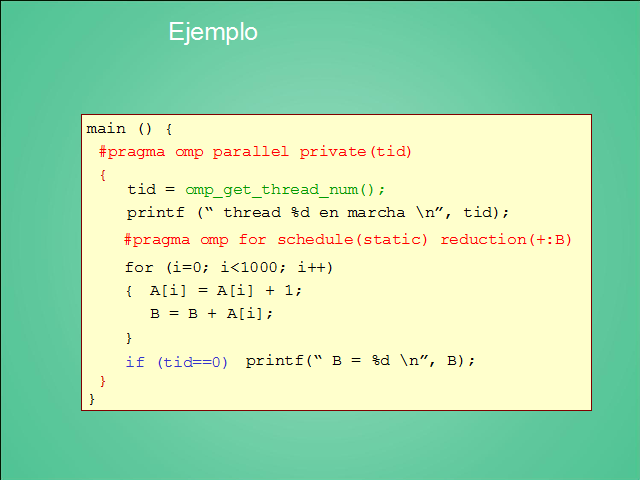
main () {
for (i=0; i< 1000; i++)
{ A[i] = A[i] + 1;
B = B + A[i];
}
printf(“ B = %d n”, B);
}
#pragma omp parallel private(tid)
{
}
tid = omp_get_thread_num();
printf (“ thread %d en marcha n”, tid);
#pragma omp for schedule(static) reduction(+:B)
if (tid==0)
Ejemplo

0 Procesos paralelos (threads).
1 REGIONES PARALELAS. Ámbito de las variables.
2 REPARTO DE TAREAS.
Datos: bucles for. Reparto de iteraciones.
Funciones: sections / single / …
3 SINCRONIZACIÓN.
Secciones críticas, cerrojos, barreras.
Conceptos básicos

0 Número de threads
? estático, una variable de entorno::
> export OMP_NUM_THREADS = 10
? dinámico, mediante una función:
omp_set_num_threads (10);
0 ¿Quién soy / cuántos somos?
tid = omp_get_thread_num();
nth = omp_get_num_threads();
Conceptos básicos

1 REGIÓN PARALELA (parallel regions)
# pragma omp parallel [VAR,…]
{ código }
Una región paralela es un trozo de código que se va a repetir y ejecutar en paralelo en todos los threads.
Las variables de una región paralela pueden ser compartidas (shared) o privadas (private).
Regiones paralelas

> Un ejemplo sencillo:
…
#define N 12
int i, tid, nth, A[N];
main ( ) {
for (i=0; i< N; i++) A[i]=0;
#pragma omp parallel
{ nth = omp_get_num_threads ();
tid = omp_get_thread_num ();
printf ("Thread %d de %d en marcha n", tid, nth);
A[tid] = 10 + tid;
printf (" El thread %d ha terminado n", tid);
}
for (i=0; i< N; i++) printf (“A(%d) = %d n”, i, A[i]);
}
private(tid,nth) shared(A)
(Gp:) barrera
Regiones paralelas

2 REPARTO DE TAREAS: bucles
Los bucles son uno de los puntos de los que extraer paralelismo de manera “sencilla” (paralelismo de datos (domain decomposition) de grano fino).
Obviamente, la simple replicación de código no es suficiente. Por ejemplo,
#pragma omp parallel shared(A) private(i)
{
for (i=0; i< 100; i++)
A[i] = A[i] + 1;
}
?
Reparto de tareas: bucles

Tendríamos que hacer algo así:
#pragma omp parallel shared(A)
private(tid,nth, ini,fin,i)
{ tid = omp_get_thread_num();
nth = omp_get_num_threads();
ini = tid * 100 / nth;
fin = (tid+1) * 100 / nth;
for (i=ini; i< fin; i++) A[i] = A[i] + 1;
}
!
El reparto de bucles se realiza automáticamente con la directiva pragma omp for.
Reparto de tareas: bucles

#pragma omp parallel […]
{ …
#pragma omp for [clausulas]
for (i=0; i< 100; i++) A[i] = A[i] + 1;
…
}
(Gp:) ámbito variables
reparto iteraciones
sincronización
(Gp:) 0..24
(Gp:) 25..49
(Gp:) 50..74
(Gp:) 75..99
(Gp:) barrera
Reparto de tareas: bucles

for (i=0; i< N; i++)
for (j=0; j< M; j++)
{
X = B[i][j] * B[i][j];
A[i][j] = A[i][j] + X;
C[i][j] = X * 2 + 1;
}
Se ejecutará en paralelo el bucle externo, y los threads ejecutarán el bucle interno. Paralelismo de grano “medio”.
Las variables i, j y X se declaran como privadas.
(Gp:) #pragma omp parallel for
private (i,j,X)
for (i=0; i< N; i++)
for (j=0; j< M; j++)
{
X = B[i][j] * B[i][j];
A[i][j] = A[i][j] + X;
C[i][j] = X * 2 + 1;
}
Reparto de tareas: bucles

for (i=0; i< N; i++)
for (j=0; j< M; j++)
{
X = B[i][j] * B[i][j];
A[i][j] = A[i][j] + X;
C[i][j] = X * 2 + 1;
}
Los threads ejecutarán en paralelo el bucle interno (el externo se ejecuta en serie). Paralelismo de grano fino.
Las variables j y X se declaran como privadas.
(Gp:)
for (i=0; i< N; i++)
#pragma omp parallel for
private (j,X)
for (j=0; j< M; j++)
{
X = B[i][j] * B[i][j];
A[i][j] = A[i][j] + X;
C[i][j] = X * 2 + 1;
}
Reparto de tareas: bucles

? ¿Cómo se reparten las iteraciones de un bucle entre los threads?
Puesto que el pragma for termina con una barrera, si la carga de los threads está mal equilibrada tendremos una pérdida (notable) de eficiencia.
? La cláusula schedule permite definir diferentes estrategias de reparto, tanto estáticas como dinámicas.
Reparto de las iteraciones

> Ejemplo
#pragma omp parallel for
shared(A) private(i)
schedule(static,2)
for (i=0; i< 32; i++)
A[i] = A[i] + 1;
Recuerda:
estático menos coste / mejor localidad datos
dinámico más coste / carga más equilibrada
pid iteraciones
0: 0,1,8,9,16,17,24,25
1: 2,3,10,11,18,19,26,27
2: 4,5,12,13,20,21,28,29
3: 6,7,14,15,22,23,30,31
Reparto de las iteraciones

#pragma omp parallel [clausulas]
{
#pragma omp sections [clausulas]
{
#pragma omp section
fun1();
#pragma omp section
fun2();
#pragma omp section
fun3();
}
}
2 REPARTO DE TAREAS: funciones
También puede usarse paralelismo de función (function decomposition), mediante la directiva sections.
Rep.de tareas: funciones
(Gp:) fun1
(Gp:) fun2
(Gp:) fun3
(Gp:) pragma omp sections

2 REPARTO DE TAREAS: funciones
Dentro de una región paralela, la directiva single asigna una tarea a un único thread.
Sólo la ejecutará un thread, pero no sabemos cúal.
Rep.de tareas: funciones

3 SINCRONIZACIÓN
Cuando no pueden eliminarse las dependencias de datos entre los threads, entonces es necesario sincronizar su ejecución.
OpenMP proporciona los mecanismos de sincronización más habituales: exclusión mutua y sincronización por eventos.
Sincronización de threads

a. Secciones críticas: pragma omp critical
Por ejemplo, calcular el máximo y el mínimo de los elementos de un vector.
#pragma omp parallel for
for (i=0; i< N; i++)
{
A[i] = fun(i);
if (A[i]>MAX)
#pragma omp critical(SMAX)
{ if (A[i]>MAX) MAX = A[i]; }
if (A[i]< MIN)
#pragma omp critical(SMIN)
{ if (A[i]< MIN) MIN = A[i]; }
}
Sincronización de threads

a. Secciones críticas: pragma omp atomic
Una sección crítica para una operación simple de tipo RMW. Por ejemplo,
#pragma omp parallel …
{
…
#pragma omp atomic
X = X + 1;
…
}
Sincronización de threads

b. Cerrojos
– omp_set_lock (&C)
espera a que el cerrojo C esté abierto; en ese momento, cierra el cerrojo en modo atómico.
– omp_unset_lock (&C)
abre el cerrojo C.
– omp_test_lock (&C)
testea el valor del cerrojo C; devuelve T/F.
Sincronización de threads

> Ejemplo
#pragma omp parallel private(nire_it)
{
omp_set_lock(&C1);
mi_it = i;
i = i + 1;
omp_unset_lock(&C1);
while (mi_it< N)
{
A[mi_it] = A[mi_it] + 1;
omp_set_lock(&C1);
mi_it = i;
i = i + 1;
omp_unset_lock(&C1);
}
}
Sincronización de threads

#pragma omp parallel private(tid)
{
tid = omp_get_thread_num();
A[tid] = fun(tid);
#pragma omp for
for (i=0; i< N; i++) B[i] = fun(A,i);
#pragma omp for
for (i=0; i< N; i++) C[i] = fun(A,B,i);
D[tid] = fun(tid);
}
c. Barreras: pragma omp barrier
(Gp:) #pragma omp barrier
nowait
Sincronización de threads

? Variables de entorno y funciones (núm. de hilos, identificadores…)
? Directiva para definir regiones paralelas
#pragma omp parallel [var…]
? Directivas de reparto de tareas
#pragma omp for [var,sched…]
#pragma omp sections [var]
? Directivas y funciones de sincronización
#pragma omp critical [c] / atomic
#pragma omp barrier
cerrojos (set_lock, unset_lock, test_lock)
Resumen

TEXTOS
• R. Chandra et al.: Parallel Programming in OpenMP Morgan Kaufmann, 2001.
• www.openmp.org (especificación 3.0, software…)
• de pago
• libres: p. e., el compilador de C/C++ de Intel
Más información

MPI
una pequeña introducción

? Si para los sistemas SMP la opción es OpenMP, el “estándar” actual de programación de los sistemas de memoria distribuida, mediante paso de mensajes, es MPI (message-passing interface).
Introducción
? MPI es, básicamente, una librería (grande) de funciones de comunicación para el envío y recepción de mensajes entre procesos.
? MPI indica explicitamente la comunicación entre procesos, es decir:
— los movimientos de datos
— la sincronización

? Dos tipos de comunicación:
• punto a punto • global
? El modelo de paralelismo que implementa MPI es SPMD.
if (pid == 1) ENVIAR_a_pid2
else if (pid == 2) RECIBIR_de_pid1
Recuerda: cada proceso dispone de su propio espacio independiente de direcciones.
Tipos de comunicación

? Modos de comunicación (1)
• síncrona
La comunicación no se produce hasta que emisor y receptor se ponen de acuerdo.
• mediante un búfer
El emisor deja el mensaje en un búfer y retorna.
La comunicación se produce cuando el receptor está dispuesto a ello. El búfer no se puede reutilizar hasta que se vacíe.
Tipos de comunicación

? Modos de comunicación (2)
• bloqueante
Se espera a que la comunicación se produzca.
La comunicación síncrona es siempre bloqueante. En el caso buffered, existen ambas alternativas.
• no bloqueante
Se retorna y se continúa con la ejecución.
Más adelante, se comprueba si la comunicación ya se ha efectuado.
Tipos de comunicación

? Cada estrategia tiene sus ventajas e inconvenientes:
> síncrona: es más rápida si el receptor está dispuesto a recibir; nos ahorramos la copia en el buffer.
Además del intercambio de datos, sirve para sincronizar los procesos.
Ojo: al ser bloqueante es posible un deadlock!
> buffered: el emisor no se bloquea si el receptor no está disponible, pero hay que hacer copia(s) del mensaje (más lento).
Tipos de comunicación

? MPI gestiona los procesos estáticamente (número y asignación) (MPI2 también dinámicamente).
Cada proceso tiene un identificador o pid.
? MPI agrupa los procesos implicados en una ejecución paralela en “comunicadores”.
Un comunicador agrupa a procesos que pueden intercambiarse mensajes.
El comunicador MPI_COMM_WORLD está creado por defecto y engloba a todos los procesos.
Introducción

? Aunque MPI consta de más de 300 funciones, el núcleo básico lo forman sólo 6:
2 de inicio y finalización del programa.
2 de control del número de procesos.
2 de comunicación.
Sintaxis: MPI_Funcion(…)
Funciones básicas

1. Comienzo y final del programa:
> MPI_Init(&argc, &argv);
> MPI_Finalize();
Estas dos funciones son la primera y última función MPI que deben ejecutarse en un programa.
F. básicas: Init / Finalize

2. Identificación de procesos
> MPI_Comm_rank(comm, &pid);
Devuelve en pid el identificador del proceso dentro del comunicador comm especificado.
Los procesos se identifican mediante dos parámetros: el pid y el grupo (comm, p.e., MPI_COMM_WORLD).
> MPI_Comm_size(comm, &npr);
Devuelve en npr el número de procesos del comunicador comm.
F. básicas: Comm_rank / _size

? Un ejemplo sencillo
#include < stdio.h>
#include < mpi.h>
main (int argc, char *argv[])
{
int pid, npr, A = 2;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &pid);
MPI_Comm_size(MPI_COMM_WORLD, &npr);
A = A + 1;
printf(“Proc. %d de %d activado, A = %dn”, pid,npr,A);
MPI_Finalize();
}
Funciones básicas

3. Envío y recepción de mensajes
La comunicación entre procesos necesita (al menos) de dos participantes: el emisor y el receptor.
El emisor ejecuta la función de envío de mensajes, y el receptor la de recepción.
(Gp:) A
(Gp:) B
(Gp:) enviar
(Gp:) recibir
La comunicación es un proceso cooperativo. Si una de las dos funciones no se ejecuta, la comunicación no tiene lugar (y podría producirse un deadlock!).
F. básicas: Send / Receive

> MPI_Send(&mess, count, type, dest,
tag, comm);
– mensaje: [mess (@com), count (tamaño), type]
– receptor: [dest, comm (grupo)]
– tag: dato de control, de 0 a 32767
(tipo de mensaje, orden…)
? Función básica para enviar un mensaje:
F. básicas: Send / Receive

> MPI_Recv(&mess, count, type, source, tag, comm, &status);
– mensaje (espacio): [mess, count, type]
– emisor: [source, comm]
– tag: clase de mensaje…
– status: información de control sobre el mensaje recibido
? Función básica para recibir un mensaje:
Recv se bloquea hasta que se recibe el mensaje.
F. básicas: Send / Receive

…
#define N 10
int main (int argc, char **argv)
{
int pid, npr, orig, dest, ndat, tag;
int i, VA[N];
MPI_Status info;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD,&pid);
for (i=0;i< N;i++) VA[i] = 0;
if (pid == 0)
{
for (i=0;i< N;i++) VA[i] = i;
dest = 1; tag = 0;
MPI_Send(VA, N, MPI_INT, dest, tag, MPI_COMM_WORLD);
}
else if (pid == 1)
{
for (i=0;i< N;i++) printf(“%4d”,VA[i]);
orig = 0; tag = 0;
MPI_Recv(VA, N, MPI_INT, orig, tag, MPI_COMM_WORLD, &info);
MPI_Get_count(&info, MPI_INT, &ndat);
printf(“Datos de pr%d; tag = %d, ndat = %d n”, info.MPI_SOURCE, info.MPI_TAG, ndat);
for (i=0;i< ndat;i++)
printf(“%4d”,VA[i]);
}
MPI_Finalize();
}
Ejemplo

? Síncrono:
MPI_Ssend (&mes,count,datatype,dest,tag,comm);
Ssend no devuelve control hasta que el receptor comienza la lectura.
? Inmediato:
MPI_Isend (…);
Retorna nada más ejecutarse; luego, para saber si se ha producido o no la comunicación:
MPI_Test (…) devuelve 0 o 1
MPI_Wait (…) espera a que finalice
Más tipos de Send / Receive

? Muchas aplicaciones requieren de operaciones de comunicación en las que participan muchos procesos.
La comunicación es colectiva si participan en ella todos los procesos del comunicador.
? Ejemplo: un broadcast, envío de datos desde un proceso a todos los demás.
¿Uno a uno en un bucle?
Comunicaciones colectivas

? Las funciones de comunicación colectiva son bloqueantes.
Todos los procesos que forman parte del comunicador deben ejecutar la función.
? Tres tipos
1 Movimiento de datos
2 Operaciones en grupo
3 Sincronización
Comunicaciones colectivas

1a Broadcast: envío de datos desde un proceso (root) a todos los demás.
(Gp:) A
(Gp:) P0
(Gp:) P2
(Gp:) P3
(Gp:) P1
(Gp:) A
(Gp:) A
(Gp:) A
(implementación logarítmica en árbol)
(Gp:) A
(Gp:) P0
(Gp:) P2
(Gp:) P3
(Gp:) P1
> MPI_Bcast(&mess, count, type, root, comm);
CC: movimento de datos

(Gp:) ABCD
(Gp:) P0
(Gp:) P2
(Gp:) P3
(Gp:) P1
(Gp:) A B C D
(Gp:) P0
(Gp:) P2
(Gp:) P3
(Gp:) P1
1b Scatter: reparto de datos desde un proceso al resto
(Gp:) C
(Gp:) B
(Gp:) D
(Gp:) A
(Gp:) A
(Gp:) P0
(Gp:) P2
(Gp:) P3
(Gp:) P1
(Gp:) C
(Gp:) D
(Gp:) B
(Gp:) A
(Gp:) P0
(Gp:) P2
(Gp:) P3
(Gp:) P1
(Gp:) C
(Gp:) D
(Gp:) B
(Gp:) ABCD
1c Gather: recolección de datos de todos los procesos
CC: movimento de datos

2. Reduce (en árbol)
Allreduce: todos obtienen el resultado (Reduce + BC)
KK: operaciones en grupo
(Gp:) A
(Gp:) P0
(Gp:) P2
(Gp:) P3
(Gp:) P1
(Gp:) C
(Gp:) D
(Gp:) B
(Gp:) A
(Gp:) P0
(Gp:) P2
(Gp:) P3
(Gp:) P1
(Gp:) C
(Gp:) D
(Gp:) B
(Gp:) A+B+C+D

3. Barreras de sincronización
Sincronización global entre todos los procesos del comunicador.
MPI_Barrier (comm);
La función se bloquea hasta que todos los procesos del comunicador la ejecutan.
CC: sincronización

> Ejemplo: V(i) = V(i) * ? V(j)
sum = 0;
for (j=0; j< N; i++) sum = sum + V[j];
for (i=0; i< N; i++) V[i] = V[i] * sum;
1. Leer N (el pid = 0)
2. Broadcast de N/npr (tamaño del vector local)
3. Scatter del vector V (trozo correspondiente)
4. Cálculo local de la suma parcial
5. Allreduce de sumas parciales (todos obtienen suma total)
6. Cálculo local de V(i) * sum
7. Gather de resultados
8. Imprimir resultados (el pid = 0)
Comunicaciones colectivas

#include < stdio.h>
#include < mat.h>
#include “mpi.h”
int main (int argc, char **argv)
{
int pid, npr, i, n;
double PI = 3.1415926536;
double h, ×, pi_loc, pi_glob, sum;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD,&pid);
MPI_Comm_size(MPI_COMM_WORLD,&npr);
if (pid == 0)
{ printf(“ Núm de intervalos”;
scanf("%d",&n);
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
h = 1.0 / (double) n; sum = 0.0; for (i=pid; i< n; i+=npr)
{ x = (i + 0.5) * h; sum += 4.0 / (1.0 + x*x); } pi_loc = h * sum;
MPI_Reduce(&pi_loc, &pi_glob, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (pid == 0) printf("pi(+/-) = %.16f, error = %.16fn", pi_glob, fabs(pi_glob – PI));
MPI_Finalize();
}
Ej.: cálculo del número pi

? De libre distribución: MPICH / LAM
? En general, previo a la ejecución en paralelo en un máquina tipo cluster, se necesita:
– un fichero con la lista de máquinas que conforman el sistema (identificadores en la red).
– unos daemons que se ejecuten en cada máquina.
– indicar, al ejecutar, el número concreto de procesos que se desea generar:
mpiexec -n 8 pi
Implementaciones de MPI

TEXTOS
• P. S. Pacheco: Parallel Programming with MPI.
Morgan Kaufmann, 1997.
• W. Groop et al.: Using MPI. Portable Parallel Programming with the Message Passing Interface (2. ed.).
MIT Press, 1999.
• M. Snir et al.: MPI – The complete reference (vol. 1 y 2).
The MIT Press, 1998.
WEB
• www-unix.mcs.anl.gov/mpi/ (todo)
Más información
 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |